今天晚上跑了一下《Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth》论文中的验证的代码,这里记录一下一些之前不知道或者不熟练的点。
1、torch.backends.cudnn.benchmark = True
这一项设置呢,是打开cudnn的benchmark mode,开启这个基准模式之后,cudnn将会自动的寻找适应于硬件的最佳算法来计算模型,而这个寻找的过程会花费一些时间,当输入固定时,可以选择开启,可以加速,而当输入不固定,经常变的时候,就无需开启了,开启之后反而可能会花费更多的时间。
参考:What does torch.backends.cudnn.benchmark do?
2、python内置的库copy
copy库主要有两个方法:
- copy.copy(x),浅拷贝
- copy.deepcopy(x[, memo]),深拷贝
深拷贝与浅拷贝的区别在于对复合对象(对象中包含着对象)处理的不同:
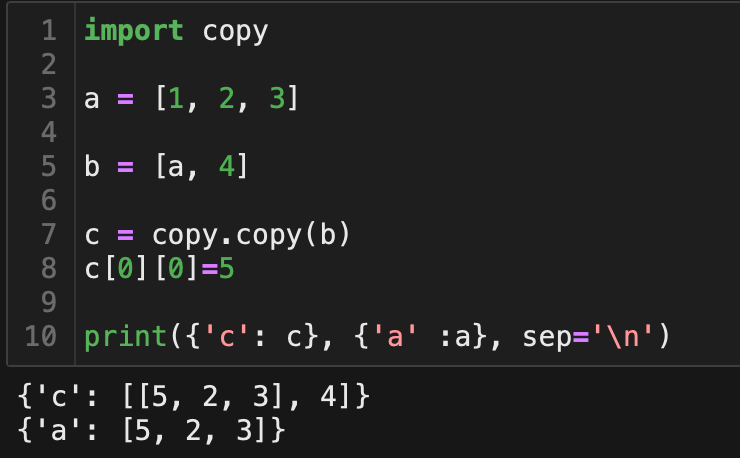
浅拷贝,新建一个复合对象,把原来复合对象中的对象直接插入进来。浅拷贝后的复合对象,改变复合对象中的对象时,会改变之前的这个对象,如下图。
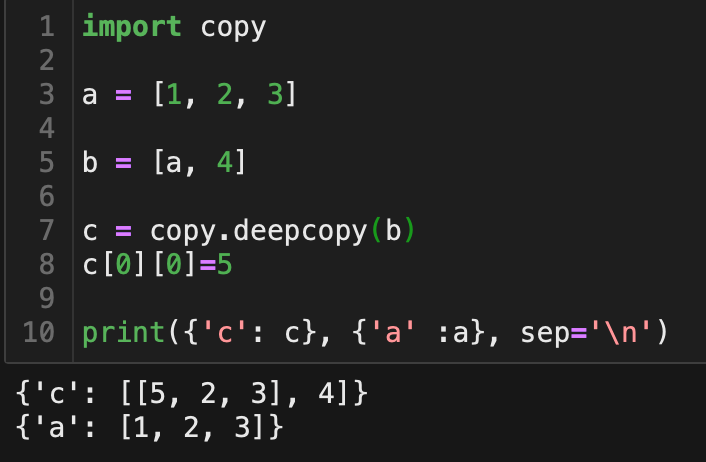
深拷贝,新建一个复合对象,把原来复合对象中的对象的副本插入进来。深拷贝后的复合对象,改变复合对象中的对象时,不会改变之前的这个对象,如下图。
参考:copy — Shallow and deep copy operations
3、 python内置的库multiprocessing与threading
这两个库分别是多进程、多线程操作的库。下面给出multiprocessing最基础的例子,threading模块这次先不展开讲。
Pool对象方便的提供了并行执行有多个输入的方法,它会将输入分发给不同的进程。
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))
Process类开启一个新进程。
from multiprocessing import Process
def f(name):
print('hello', name)
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
参考:multiprocessing — Process-based parallelism
参考:threading — Thread-based parallelism
小结
还有太多的东西要学,继续加油,多学习,多总结,哈哈!