今天加了一个“支线任务”页面,之前的图标没有支持在MacOS 11中Safari浏览器的标签页的显示,然后换成了现在这个图标,主要参考:添加新的页面、更换图标,图标来源于flaticon。
这两天呢,一直在弄数据集,为什么弄数据集呢,这个故事的开始是悲伤的,我在VS Code中连接服务器,想要删除数据集中多余的文件,先是选择了数据集文件夹,然后又直接选择了想删除的文件,接着点击了永久删除,这时就悲剧了,我尝试了去恢复数据,奈何没有管理员权限,最后选择了重新下载(下载过程真是…),顺带把几个数据集都大致了解一下,总结一下。
VOC 2012
Visual Object Classes Challenge 2012 (VOC2012)
1.1、简单介绍
数据集包含了20个分类(如下),后面的括号是按A-Z排序后的编号,也是语义分割标注的像素值(0表示背景,255表示对象的轮廓,如下图)
- Person: person(15)
-
Animal: bird(3), cat(8), cow(10), dog(12), horse(13), sheep(17)
-
Vehicle: aeroplane(1), bicycle(2), boat(4), bus(6), car(7), motorbike(14), train(19)
- Indoor: bottle(5), chair(9), dining table(11), potted plant(16), sofa(19), tv/monitor(20)
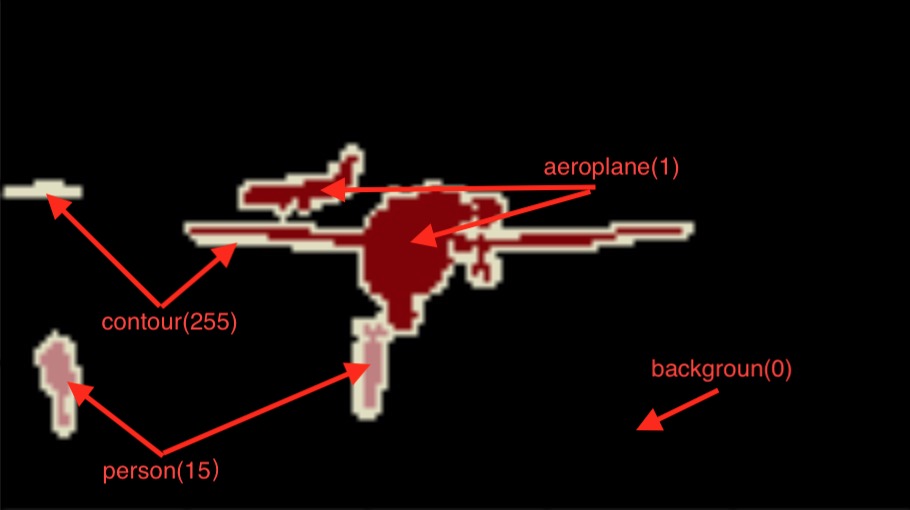
这个数据可以完成如下任务:
- 分类(可以区分上面的20类,还可以区分动作
Action Classification,包括如下动作)- Jumping
- Phoning
- PlayingInstrument
- Reading
- RidingBike
- RidingHorse
- Running
- TakingPhoto
- UsingComputer
- Walking
- 检测(不仅可以检测整个对象,还能检测人的部分
Person Layout,不过只限于检测头、手、脚)- head
- hands
- feet
- 分割(包括语义分割与实例分割)
- 总共有2913张图片,训练集1464张,验证集1449张,当然可以根据自己的想法调整训练集验证集图片的数量。
1.2、下载数据集
-
通过命令下载
wget -c http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar -
通过torchvision.datasets下载
设置一下下载到哪个文件夹下(
root参数),然后将download参数设置为True。我个人比较推荐这种方法,比较简单,主要是它会自动解压好。
import torchvision root = './' torchvision.datasets.VOCSegmentation(root, year='2012', image_set='trainval', download=True, transform=None, target_transform=None, transforms=None)
1.3、加载数据集
使用torchvision.datasets加载数据集较为简单,“站在巨人的肩膀上”。
-
做分类的话,使用如下代码,pytorch文档
torchvision.datasets.VOCDetection(root, year='2012', image_set='train', download=False, transform=None, target_transform=None, transforms=None) -
做分割的话,可以使用一下代码,从pytorch,
torchvision.datasets.VOCSegmentation源码中改过来的。官方代码只适应语义分割任务,下面的代码通过
target_type参数控制返回不同的目标。(语义分割target_type='Class',实例分割target_type='Object')import os from torchvision.datasets.vision import VisionDataset from PIL import Image class VOCSegmentation(VisionDataset): def __init__(self, root, target_type='Object', image_set='train', transform=None, target_transform=None, transforms=None): super(VOCSegmentation, self).__init__(root, transforms, transform, target_transform) assert target_type in ['Object', 'Class'], "target_type must in ['Object', 'Class']" base_dir = 'VOCdevkit/VOC2012' voc_root = os.path.join(self.root, base_dir) image_dir = os.path.join(voc_root, 'JPEGImages') mask_dir = os.path.join(voc_root, 'Segmentation'+target_type) if not os.path.isdir(voc_root): raise RuntimeError('Dataset not found or corrupted.' + ' You can use download=True to download it') splits_dir = os.path.join(voc_root, 'ImageSets/Segmentation') split_f = os.path.join(splits_dir, image_set.rstrip('\n') + '.txt') with open(os.path.join(split_f), "r") as f: file_names = [x.strip() for x in f.readlines()] self.images = [os.path.join(image_dir, x + ".jpg") for x in file_names] self.masks = [os.path.join(mask_dir, x + ".png") for x in file_names] assert (len(self.images) == len(self.masks)) def __getitem__(self, index): img = Image.open(self.images[index]).convert('RGB') target = Image.open(self.masks[index]) if self.transforms is not None: img, target = self.transforms(img, target) return img, target def __len__(self): return len(self.images)
1.4、提取对象的标记
获取对象对应的像素值,列表第一个值为背景值,这种方式比较简单,还有一种是通过颜色color map来判断的,这部分内容放到最后拓展来讲。
def get_target_ids(target):
# 提取对象对应的像素值,将背景(0),轮廓(255)结合到一起
ids = [ iid if iid != 0 else [0, 255] for iid in np.unique(target) ]
ids = ids[0:-1]
# print(ids)
return ids
1.4.1、二值masks(0为背景,1为对象)
# 二值mask(0为背景,1为对象)
def get_object_masks(target, ids) -> 'np.ndarray (n, h, w)':
target = np.array(target)
# 提取mask列表,并堆叠到一起
mask_list = []
for j, iid in enumerate(ids):
if j == 0:
mask = np.isin(target, iid)
else:
mask = np.where(target == iid, 1, 0)
mask_list.append(mask)
masks = np.stack(mask_list, axis=0)
return masks
1.4.2、数字标号的mask(0为背景,1…n为对象的值)
# 数字标号的mask(0为背景,1...n为对象的值)
def get_object_nums_mask(target, ids) -> 'np.ndarray (h, w)':
target = np.array(target)
# 将对象对应的标号加到一起(一个像素不会对应两个值)
nums_mask = np.zeros_like(target)
for j, iid in enumerate(ids):
if j == 0:
continue
else:
mask = np.where(target == iid, j, 0)
nums_mask = nums_mask + mask
return nums_mask
COCO 2017
Common Objects in Context (COCO)
2.1、简单介绍
COCO数据集也是支持多种任务:分类、检测(物体检测、关键点检测、姿态检测)、图片字幕、分割(包括全景分割、实例分割、语义分割)
COCO2017 训练集有118287张图片,验证集有5000张图片。
不多说了,直接进行下一步吧。
2.2、下载数据集
下面是用命令下载,可能下载会比较慢,可以使用迅雷下载,然后上传到服务器,也可以使用axel工具。(参考:知乎-命令行的“迅雷”,提升百倍以上下载速率)
-
下载并解压训练集
wget -c http://images.cocodataset.org/zips/train2017.zip mkdir COCO2017 mv train2017.zip ./COCO2017/train2017.zip unzip -d ./COCO2017/ ./COCO2017/train2017.zip -
下载并解压验证集
wget -c http://images.cocodataset.org/zips/val2017.zip mv val2017.zip ./COCO2017/val2017.zip unzip -d ./COCO2017/ ./COCO2017/val2017.zip -
下载并解压训练集与验证的集的标注
wget -c http://images.cocodataset.org/annotations/annotations_trainval2017.zip mv annotations_trainval2017.zip ./COCO2017/annotations_trainval2017.zip unzip -d ./COCO2017/ ./COCO2017/annotations_trainval2017.zip
2.3、加载数据集
2.3.1、下载COCO API
-
pip
pip3 install pycocotools -
conda
conda install -c conda-forge pycocotools -y
2.3.2、加载数据集
加载数据集的target并不是图像,而是json字符串,包含了图片的信息,包括图片高宽、边框信息、图片ID、多边形点标注或者Run-length encoding (RLE)格式,具体格式根据任务不同,可以通过COCO官方给出的Data format介绍
-
通过torchvision.datasets
import torchvision import matplotlib.pyplot as plt root = r'COCO2017/train2017' annFile_train = r'./COCO2017/annotations/instances_train2017.json' annFile_val = r'./COCO2017/annotations/instances_val2017.json' coco_dataset_train = torchvision.datasets.CocoDetection(root, annFile_train, transform=None, target_transform=None, transforms=None) coco_dataset_val = torchvision.datasets.CocoDetection(root, annFile_val, transform=None, target_transform=None, transforms=None)图像字幕可以通过torchvision.datasets.CocoCaptions(root, annFile, transform=None, target_transform=None, transforms=None)来加载。 -
通过pycocotools
import os from pycocotools.coco import COCO from PIL import Image root = r'COCO2017/train2017' annFile_train = r'./COCO2017/annotations/instances_train2017.json' annFile_val = r'./COCO2017/annotations/instances_val2017.json' coco = COCO(annFile_train) ids = list(sorted(coco.imgs.keys())) for i, img_id in enumerate(ids): img_path = coco.loadImgs(img_id)[0]['file_name'] img = Image.open(os.path.join(root, img_path)).convert('RGB') # 加载原图 ann_ids = coco.getAnnIds(imgIds=img_id) target = coco.loadAnns(ann_ids) #加载targetpycocotools github地址
最主要的python源文件有两个:coco.py、mask.py、cocoeval.py,下面是这几个文件里API的说明。
-
coco.py
# The following API functions are defined: # COCO - COCO api class that loads COCO annotation file and prepare data structures. # decodeMask - Decode binary mask M encoded via run-length encoding. # encodeMask - Encode binary mask M using run-length encoding. # getAnnIds - Get ann ids that satisfy given filter conditions. # getCatIds - Get cat ids that satisfy given filter conditions. # getImgIds - Get img ids that satisfy given filter conditions. # loadAnns - Load anns with the specified ids. # loadCats - Load cats with the specified ids. # loadImgs - Load imgs with the specified ids. # annToMask - Convert segmentation in an annotation to binary mask. # showAnns - Display the specified annotations. # loadRes - Load algorithm results and create API for accessing them. # download - Download COCO images from mscoco.org server. # Throughout the API "ann"=annotation, "cat"=category, and "img"=image. # Help on each functions can be accessed by: "help COCO>function". -
mask.py
# The following API functions are defined: # encode - Encode binary masks using RLE. # decode - Decode binary masks encoded via RLE. # merge - Compute union or intersection of encoded masks. # iou - Compute intersection over union between masks. # area - Compute area of encoded masks. # toBbox - Get bounding boxes surrounding encoded masks. # frPyObjects - Convert polygon, bbox, and uncompressed RLE to encoded RLE mask. -
cocoeval.py
# The usage for CocoEval is as follows: # cocoGt=..., cocoDt=... # load dataset and results # E = CocoEval(cocoGt,cocoDt); # initialize CocoEval object # E.params.recThrs = ...; # set parameters as desired # E.evaluate(); # run per image evaluation # E.accumulate(); # accumulate per image results # E.summarize(); # display summary metrics of results # For example usage see evalDemo.m and http://mscoco.org/.
-
2.4、提取对象的标签标记
这里主要以通过torchvision.datasets加载数据集方式下的target,而通过pycocotools加载数据集下的target有些不同,他包括了更多信息,可以通过下面这句代码转为通过torchvision.datasets加载数据集方式下的target。
target = target['Objects']
以下两个方法中的coco_object参数是COCO类实例化的对象,可以使用torchvision.datasets数据集对象中的coco属性调用,如:coco_dataset_train.coco,或者是pycocotools中COCO类实例化的对象。
2.4.1、二值masks(0为背景,1为对象)
def get_object_masks(coco_object, target):
bg = 0
mask_list = []
for j, ann in enumerate(target):
mask = coco_object.annToMask(ann)
mask_list.append(mask)
bg = bg + mask
bg = np.where(bg == 0, 1, 0)
mask_list.insert(0, bg)
masks = np.stack(mask_list, axis=0)
return masks
2.4.2、数字标号的mask(0为背景,1…n为对象的值)
COCO数据集中有对象有重叠,下面的方法有去掉重叠像素(后面的对象像素点位置在赋值的时候,如果已经有对象赋值了则不再赋值,如下图第三张),去掉重叠对象(后面的对象如果与已有对象有重叠则跳过,如下图第五张),以上方法是不够好的,可能应该直接不使用数字标号的mask(这种mask主要为softmax服务),而使用二值mask做二分类。(如下图所示,第一张图为原图,第二站图为有标注遮罩的图,第三张图为没有去重叠的图, 第四张图为去掉重叠元素的像素点的图,下面的第一段代码,第五张图为去掉重叠元素的像素点的图,下面的第二段代码)

def get_object_nums_mask_remove_overlap_pixel(coco_object, target):
nums_mask = []
for j, ann in enumerate(target):
mask = coco_object.annToMask(ann)
if j == 0:
nums_mask = np.zeros_like(mask)
# 去掉了后面有重叠的像素点
nums_mask = nums_mask + np.where((mask - (nums_mask > 0))==1, j+1, 0)
return nums_mask
def get_object_nums_mask_remove_overlap_object(coco_object, target):
nums_mask = []
nums_object = 1
for j, ann in enumerate(target):
mask = coco_object.annToMask(ann)
if j == 0:
nums_mask = np.zeros_like(mask)
# 去掉了后面有重叠的像素点的对象
if ((mask - (nums_mask == 0)) == 1).any():
break
nums_mask = nums_mask + np.where(mask == 1, nums_object, 0)
nums_object = nums_object + 1
return nums_mask
Cityscapes
3.1、简单介绍
Cityscapes数据集呢,主要是车行驶在各个城市的图像,图像比较大(1024*2048),主要用于分割,检测等任务,这里就不多说了,看下面的数据集信息吧。

| 文件名 | packageID | md5值 |
|---|---|---|
gtFine_trainvaltest.zip |
1 | 4237c19de34c8a376e9ba46b495d6f66 |
gtCoarse.zip |
2 | 1c7b95c84b1d36cc59a9194d8e5b989f |
leftImg8bit_trainvaltest.zip |
3 | 0a6e97e94b616a514066c9e2adb0c97f |
leftImg8bit_trainextra.zip |
4 | 9167a331a158ce3e8989e166c95d56d4 |
md5值可以使用md5sum工具来验证参考:CSDN-Linux下使用md5sum计算和检验MD5码
gtFine_trainvaltest.zip(241MB):主要为标的好一些的标注,包括标注训练与验证集共3475张图片,测试集1525张图片忽略了区域,这个数据集和leftImg8bit_trainvaltest.zip(11GB)相呼应
gtCoarse.zip(1.3GB):主要为标的粗糙一些的标注,包括标注训练与验证集标注共3475张图片,标注了额外的训练数据集19998张图片,与leftImg8bit_trainextra.zip (44GB) 和leftImg8bit_trainvaltest.zip(11GB)相呼应。
3.2、下载数据集
可以通过Cityscapes官网注册登录然后下载,也可以通过命令下载参考:CSDN-Linux下载交通图片数据集CityScapes Dataset
命令如下
3.2.1、登录
注意需要先注册。
wget --keep-session-cookies --save-cookies=cookies.txt --post-data 'username=yourname&password=yourpassword&submit=Login' https://www.cityscapes-dataset.com/login/
3.2.2、下对应数据集
修改下面对应的ID值就可以下载对应的包,相关包的ID可以看上面的表格。
wget --load-cookies cookies.txt --content-disposition https://www.cityscapes-dataset.com/file-handling/?packageID=3
3.2.3 解压图片和标注
mkdir Cityscapes
mv leftImg8bit_trainvaltest.zip ./Cityscapes/leftImg8bit_trainvaltest.zip
unzip -d ./Cityscapes ./Cityscapes/leftImg8bit_trainvaltest.zip
mv ./Cityscapes/README ./Cityscapes/README_leftImg8bit
mv ./Cityscapes/license.txt ./Cityscapes/license_leftImg8bit.txt
mv gtFine_trainvaltest.zip ./Cityscapes/gtFine_trainvaltest.zip
unzip -d ./Cityscapes ./Cityscapes/gtFine_trainvaltest.zip
mv ./Cityscapes/README ./Cityscapes/README_gtFine
mv ./Cityscapes/license.txt ./Cityscapes/license_gtFine.txt
3.3、加载数据集
加载数据集之前需要下载安装cityscapesScripts
python -m pip install cityscapesscripts
依旧使用torchvision.datasets来加载数据集,简单和方便,代码如下。加载数据集的类型可分为’instance’, ‘semantic’, ‘color’, ‘polygon’这几种,也可以是这集中的任意组合,其中color是输出全景分割label,polygon是输出分割对象的多边形轮廓的点信息。
import torchvision
import numpy as np
root = r'./Cityscapes/'
# target_type = ['instance', 'semantic', 'color', 'polygon']
target_type = 'instance'
cityscapes_dataset = torchvision.datasets.Cityscapes(root, split='train', mode='fine', target_type=target_type, transform=None, target_transform=None)
还可以通过将Cityscapes数据集转换为COCO数据,然后通过COCO来加载,参考:https://github.com/jinfagang/cityscapestococo
3.4、提取对象的mask标记
def get_target_ids(target):
ids = [iid for iid in np.unique(target) if iid >= 1000]
# print(ids)
return ids
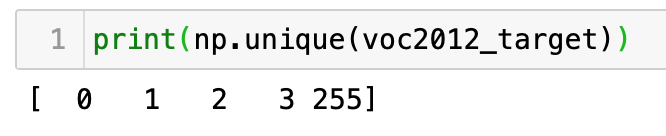
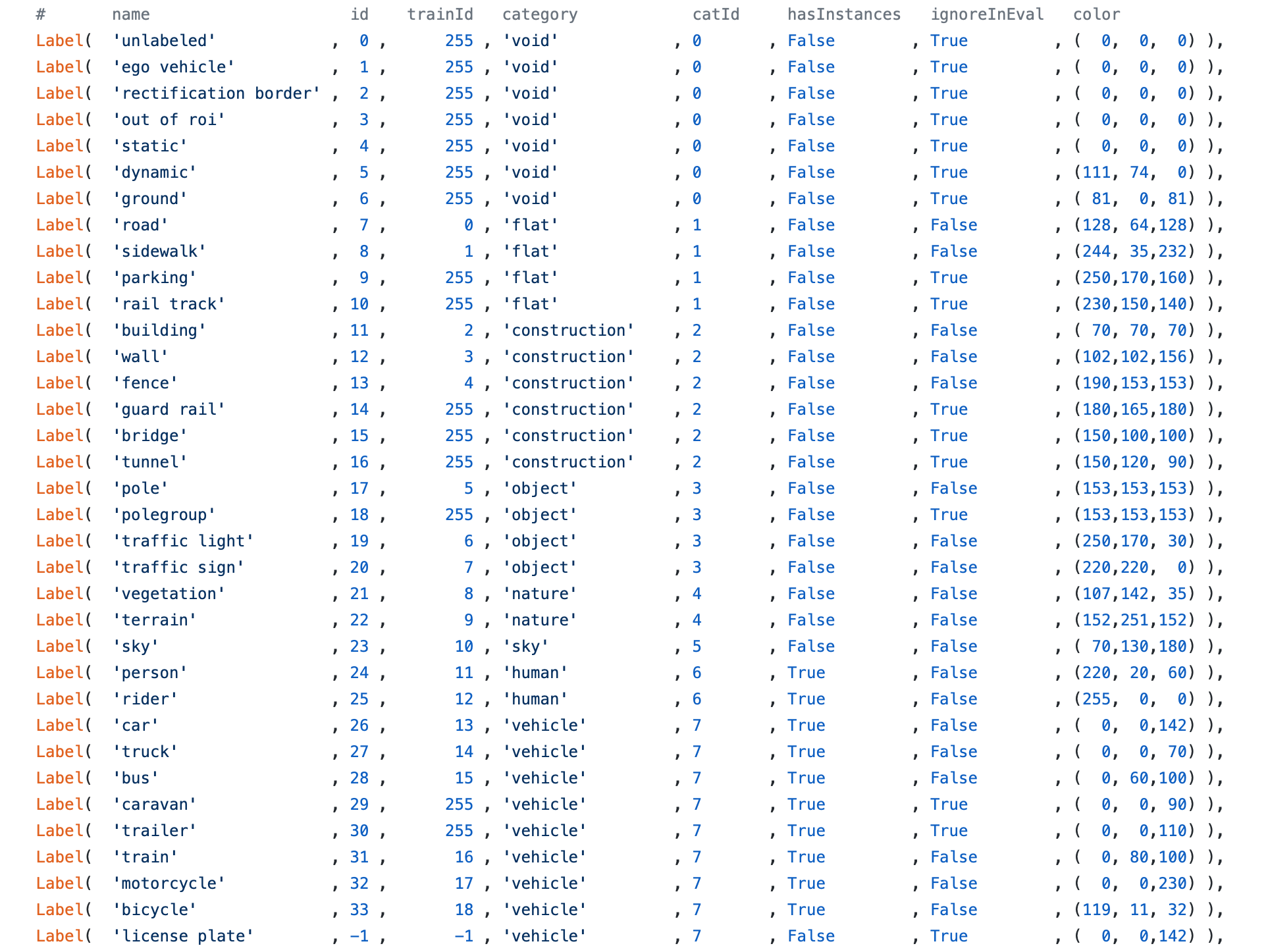
提取对象的mask方式与VOC2012的方式基本一样(代码如上),只是获取ids的方式不同。VOC2012的实例分割标注,没有带有类别信息,只是按第一个、第二个、到第n个对象的顺序标号(从零开始)来标记的(如下图一),而Cityscapes的实例分割包括了分类标签信息(如下图三,来自labels.py),它是通过对象id*1000+第几个对象的顺序标号来标记的(如下图二)。
VOC2012中,0表示背景,255表示对象轮廓
Cityscapes中,小于1000的数字是语义分割的标号,而大于1000的是对应对象的实例分割标注(对象id*1000+第几个对象的顺序标号)。如26003是对象car的第四个对象(下标从零开始)。

拓展:颜色转换
将(0-255)的PIL.PngImagePlugin.PngImageFile转成RGB模式下的PIL.Image.Image的颜色转换,如下代码color_map_rgb可以获取获取到0-N的对应的颜色。
def bitget(number, pos):
return (number >> pos - 1) & 1
def bitor(number1, number2):
return number1 | number2
def bitshift(number, shift_bit_count):
if shift_bit_count < 0:
number = number >> abs(shift_bit_count)
else:
number = number << shift_bit_count
return number
def color_map_rgb(N):
cmap = np.zeros((N+1,3), np.uint8)
for i in range(N+1):
if i == 0:
continue
id = i
r = g = b = 0
for j in range(8):
r = bitor(r, bitshift(bitget(id, 1), 7 - j))
g = bitor(g, bitshift(bitget(id, 2), 7 - j))
b = bitor(b, bitshift(bitget(id, 3), 7 - j))
id = bitshift(id, -3)
cmap[i, :]=[r, g, b]
# print([r,g,b])
return cmap
简单来看0-255对应的颜色值的规律:(以下面0-10所对应的RGB颜色值来看)
| 数字值 | 二进制 | RGB颜色值 |
|---|---|---|
| 0 | b000000 | [ 0, 0, 0] |
| 1 | b000001 | [128, 0, 0] |
| 2 | b000010 | [ 0, 128, 0] |
| 3 | b000011 | [128, 128, 0] |
| 4 | b000100 | [ 0, 0, 128] |
| 5 | b000101 | [128, 0, 128] |
| 6 | b000110 | [ 0, 128, 128] |
| 7 | b000111 | [128, 128, 128] |
| 8 | b001000 | [ 64, 0, 0] |
| 9 | b001001 | [192, 0, 0] |
| 10 | b001010 | [ 64, 128, 0] |
规律 将二进制逆序,以三位为一捆,然后每一位的数字对应乘以255*(1/2)^n(第几捆),然后把所有捆对应位的对应的值加起来。
以10为例,10的二进制是b001010,逆序010100,分为两捆,第一捆010,第二捆100,第一捆对应乘以128(255(1/2)^1)得到(0128, 1128, 0128),第二捆对应乘以64(255(1/2)^2)得到(164, 064, 064),最后对应相加得到RGB值(64, 128, 0)
再来个大点的数66,66的二进制b1000010,逆序0100001,第一捆010,第二捆000,第三捆100,分别对应,(0128, 1128, 0128),(064, 064, 064),(32*1, 0, 0),对应相加得到(32, 128, 0),验证结果正确(如下图所示)。

总结
小小总结一下,这次主要总结了三个数据集VOC2012、COCO2017、Cityscapes的使用方法,主要以实例分割方向上来讲解,不知道怎么总结好了,不说了,休息。