数字图像处理课要结课了,结课任务是讲解一篇,然后我们拿到的论文是这一篇:DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation,今天看了一下,论文主要提出一种特征聚合(Feature Aggregation)的结构,这里总结一下。
提出并解决问题
实时语义分割:希望同时做到分割速度快、分割质量高。有许多方法已经在一些benchmarks(例如:pascal voc、cityscapes、coco等等数据集)上取得好的效果。(拓展知识: 浅谈 baseline & benchmark & backbone中的理解)
提出问题
-
有些方法使用U-shape结构1(U型结构,例如下图结构),这种结构在处理高分辨率特征图时候,会消耗大量时间。(论文中这么说,我个人觉得还是跟网络深度有关系,这里没有明白为什么作者要特意的挑出U型结构。)
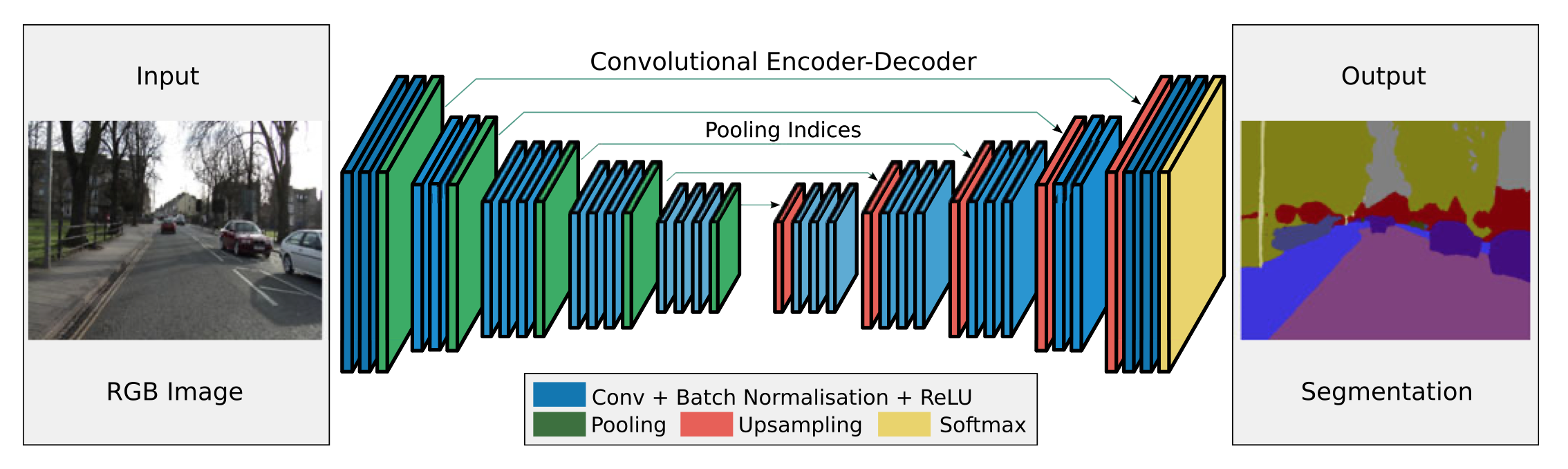
- 有些工作通过限制固定的图像大小。
- 有些工作会去掉特征图的一些“冗余”信息(比如使用Spatial Dropout,在DeepLabV3+论文中提到说不是所有的的特征都对解码模块有重要的作用)。
一些方法通过以上两个方法来加快计算速度,但是相应的也存在一些问题。会丢失掉一些边界和小对象的空间细节
-
浅层网络(shallow network)的特征区分能力会比较弱,然而使用深层的网络(deep network)则会影响速度。
解决问题
为了解决以上问题,最大程度的利用特征,并尽可能的减少计算量,很多相应的结构产生了,如下图所示。
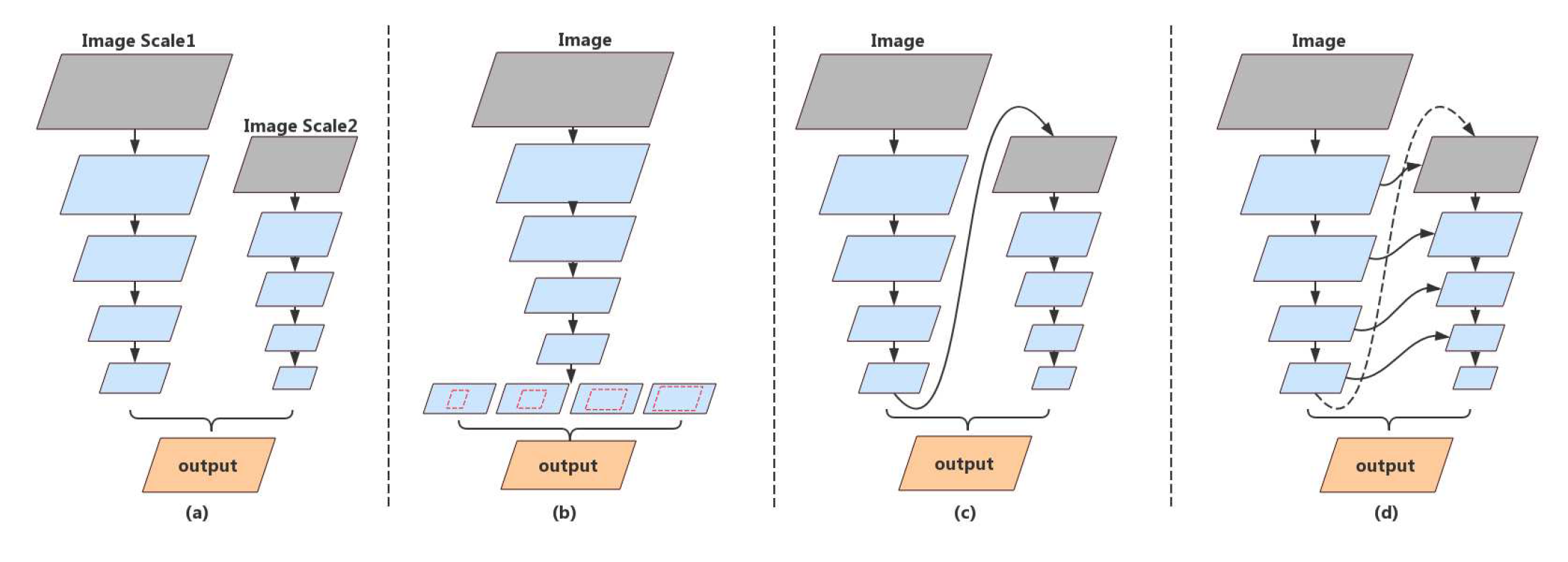
- 多分支(Multi-branch)结构,图中(a),使用这种多分支结构结合了空间细节和上下文信息,然而加入了额外的分支,会使得速度受到限制,并且相互独立的两个分支会限制模型的学习能力。
- 空间金字塔池化(spatial pyramid pooling)结构,图中(b),使用空间金字塔池化结构呢,加强了带有高层次上下文的特征(features with high-level context),但是这样也会显著的加大计算量,而且加强的特征是来自于单路径输出的特征图,缺乏低层次特征,而低层次特征同样保留空间细节和分割信息。
- 网络级的特征重用(feature reuse in network level)结构,图中(c),使用网络级的特征重用结构,则包括了低层次的特征。从图(c)中看,其实就是使用了单个网络结构的低层次与高层次的特征,那它为什么叫网络级的特征重用呢,其实是因为左边与右边的网络结构是一样的,只是输入的大小变小了。
- 阶段级的特征重用(feature reuse in stage level)结构,图中(d),这种结构在结合了网络级的特征重用结构的基础上,还在不同的阶段聚合特征,加强了特征表示能力,重用(reuse)高层次的特征打破了语义信息与空间结构细节的隔阂(gap)(即同时使用了低层次与高层次的特征)。
论文中提出的网络级的特征重用结构,图中(c)、阶段级的特征重用结构,图中(d),显然会消耗更多的空间以及算力,但是由于可以更好的利用特征,所以降低网络的深度,从而达到整体计算量减少的效果。
DFANet与其他语义分割模型比较
论文中方法DFANet(Deep Feature Aggregation Network)与其他语义分割模型性能与计算量比较,如下图。
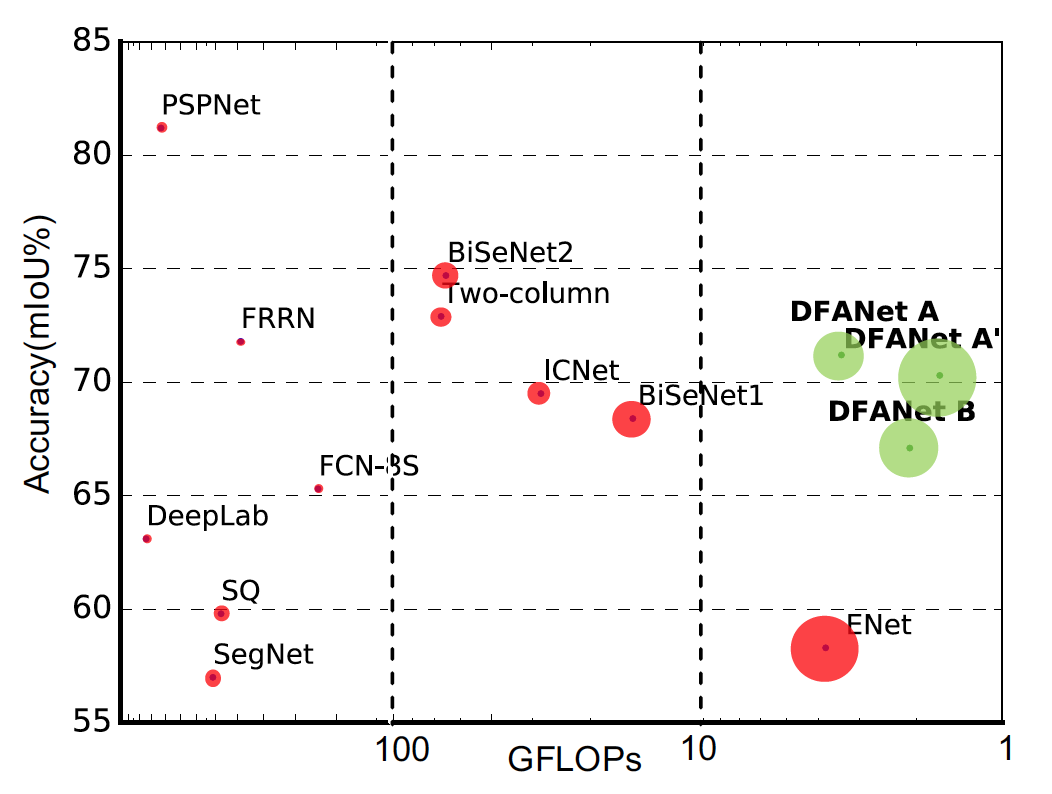
横坐标单位为GFLOPs(Giga FLoating-point Operations),十亿浮点运算次数,衡量模型的复杂度(计算量),这个概念需要和全大写的FLOPS(floating point operations per second),意指每秒浮点运算次数,是一个衡量硬件性能的指标(每秒的计算速度)。 纵坐标是准确率(交叠率,mIoU),可以看出效果在性能与计算量是比较均衡的。 其中DFANet A与DFANet B是在使用不同的backbone的情况下进行比较,DFANet A使用的backbone的计算量是DFANet B的两倍(1.6GFLOPs:0.83GFLOPs),DFANet A与DFANet A‘是在不同的输入图像大小的情况下进行比较的,DFANet A的输入图片的大小为1024x1024,DFANet A‘的输入大小为512x1024。
相关的工作与概念
相关工作
实时的语义分割相关工作:
- SegNet使用比较小的架构(small architecture)和池化索引策略(pooling indices strategy)来减少网络参数。
- ENet减少下采样的次数,追求的紧致的框架,然后去掉了模型的最后一个阶段,使得感受野变小,以至于导致对大的对象分割效果不够好。
- ESPNet使用了新的空间金字塔结构。
- ICNet使用多尺度的图像作为输入,并且使用一个级联网络来提升效率。
- BiSeNet使用空间路径(spatial path)和语义路径(semantic path)来减少计算量。
相关概念
- 深度分离卷积(Depthwise Separable Convolution):深度卷积操作由逐深度卷积(depthwise convolution)加逐点卷积(pointwise convolution)构成,可以在保持很小的性能(效果)损失的情况下,减少参数和计算量。Xception模块中的卷积就是深度分离卷积,因而兼顾了语义分割速度和准确度。相关概念可以查看这个帖子Depthwise卷积与Pointwise卷积。
- 高层次特征(High-level Features):高层次的特征刻画了输入图片的语义信息,分割任务关键在于感受野与分类能力,PSPNet、与DeepLab系列网络使用额外的操作将山下问信息和多尺度特征表示信息合并到一起。空间金字塔池化已经广泛的应用,作为对整体场景理解(overall scene interpretation)一个好的描述。
- 上下文编码(Context Encoding):SENet使用逐深度注意力(channel-wise attention)提升了模型特征的表示。EncNet使用上下文编码来加强对每个像素点分割结果的预测,这本篇论文中使用全连接模块作为attention,来提升backbone性能(会对性能有一点点影响)。
- 特征聚合(Feature Aggregation):实现特征聚合有跳跃连接(skip connection),另外还有密集连接(dense connection),另外RefineNet提出在上采样解读提取多尺度特征的模块。
论文中提出的方法
模型
论文提出的模型主要分三部分轻量级权重的backbone(the lightweight backbones), 子网络级的聚合(sub-network aggregation )模块和子阶段级的聚合(sub-stage aggregation )模块,而其中子网络级的聚合模块和子阶段级的聚合模块是相融在一起的,如下图。
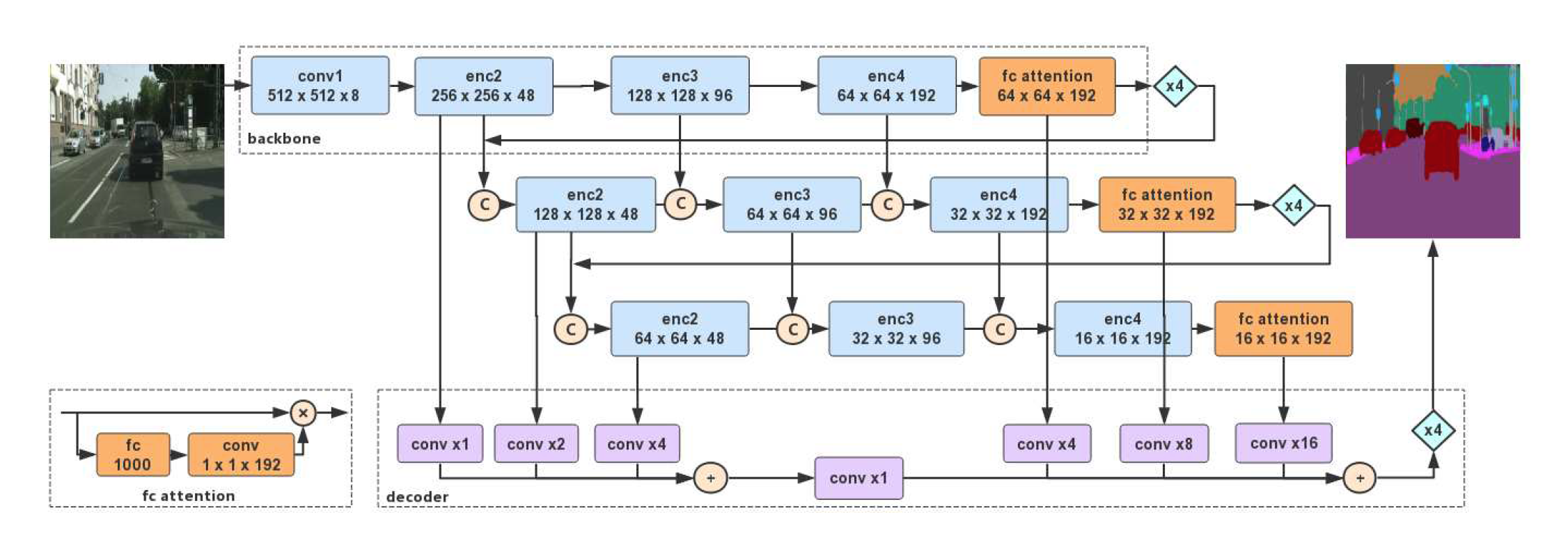
模型图中,“C”表示串联到一起(concatenation),“xN”代表上采样N倍。“+”表示对应元素相加,‘x’表示对应元素相乘,fc attention模块是Xception中的全连接层,加上一个1x1卷积2在于之前的特征逐元素相乘([B, 1000, 1, 1] 通过1x1卷积得到[B, 192, 1, 1]),其他各个模块的细节如下图,
,conv1是普通的卷积操作,enc2、enc3、enc4中的卷积都是深度分离卷积操作,Xception A与Xception B是两种不同的Bakcbone。3
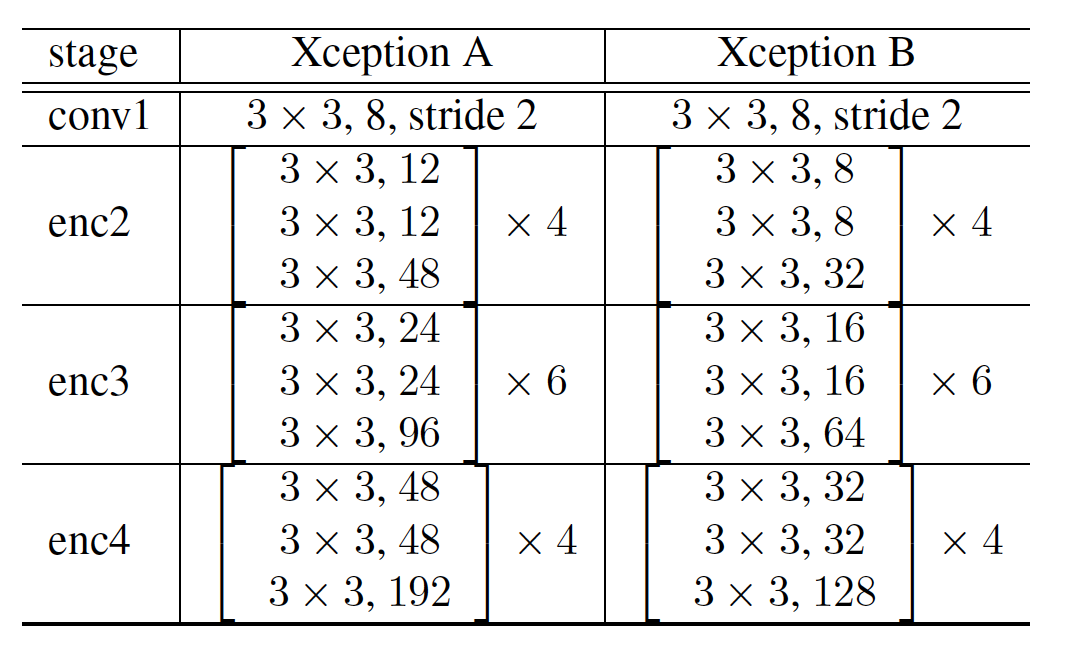
在模型图中decoder那部分紫色的conv都没有体现卷积的通道,我看了代码它是输出64个通道的1x1卷积,所以输出大小维持原大小。在解码阶段的卷积只是做了减少通道数量的操作。
训练细节
- 损失是用的交叉熵损失
- backbone是用的作者自己修改后的Xception模型,并在ImageNet-1k数据集4上进行训练,然后用于DFANet模型的预训练。
- fc attention5模块中的全连接层参数也是来自backbone中的全连接层参数。
总结与感受
DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation 这篇论文主要提出了一种特征聚合网络结构,结合了网络级的特征重用模块、阶段级的特征重用模块,达到了比较好的分割性能的情况下,同时有比较好的实时性。
这次总结大多已翻译为主了,大多是翻译了一些我认为可以拿出来讲一下的东西总结在了这里,也算是了解了一种新的特征聚合模块吧,不过还是对当前工作是有启发的,我们当前的特征是用的backbone最后的输出,没有结合低层次的特征,之前一直想使用结合多个层次的特征,而这篇论文正提供了一种方法。
暂且总结到这里,做ppt,准备下周的汇报了。
-
如何理解U型结构呢,我个人的理解是,图像大小在编码的时候不断的变小,随后再解码的过程图像大小又不断的变大,有这种比较对称的变小变大的过程的网络,我把他理解为U型结构。 ↩
-
这里论文中说是1x1卷积,实现的时候是使用的全连接,仔细一想,对于维度为(b,1000,1,1)的向量的全链接与1x1的卷积是一样的。 ↩
-
看代码,我才发现enc2、enc3、enc4中的卷积输出的通道数都是最后一层是前面的两倍,而且Xception中的enc2、enc3、enc4的实现是,第一个深度分离卷积有stride=2,第二、三层没有,最后又一个对输入过一次1x1卷积,stride=2,再于第三层的结构对于元素相加。结构可以类似于下图。
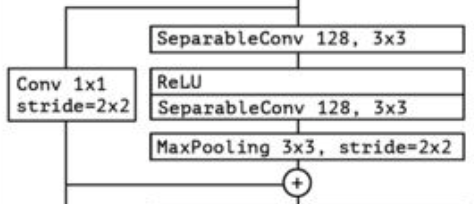 ↩
↩ -
ImageNet数据集有14M(1400多万)张图片,有22k种类别,而ImageNet—1k数据集是只有1k种类别,对应图片一百多万张。 ↩
-
Attention,简而言之,深度学习中的注意力可以被广义地理解为表示重要性的权重向量(一般会做一个归一化,比如通过一个sigmoid函数)。为了预测或推断一个元素,例如图像中的像素或句子中的单词,我们使用注意力权重来估计其它元素与其相关的强度,并将由注意力权重加权的值的总和作为计算最终目标的特征。Step1:计算其它元素与待预测元素的相关性权重。Step2:根据相关性权重对其它元素进行加权求和。我个人简单的理解是:第一,它是表示重要性的权重,第二,它会随输入不同而不同,所以它应该是算出来的,不是我们自己给的,也不是学习到的。 ↩