【AI实测】智谱免费的图片和视频 API 到底行不行?一篇实测讲透
前面我认认真真测了 Agnes AI 的免费图片和视频模型——结论是”图片不写汉字能用、写汉字崩;视频画面勉强能用、精细度差一截”。先给 Agnes 定个档:按我测下来的印象,它的图片生成大概在 2025 年上半年的水平,视频可能还停在 2024 年。 把这个参照档位摆出来,后面”智谱比 Agnes 快/慢、强/弱”的横评,才换算得成绝对水平。测完 Agnes 我就在想:国产大厂里,智谱(BigModel)也挂着”免费文生图 + 免费文生视频”的招牌,它又是什么水平?
智谱是国内做大模型排前列的厂商,GLM 系列一直在更新。它的开放平台 open.bigmodel.cn 上,图像和视频生成这一档,免费模型只有两个:
cogview-3-flash—— 免费文生图(付费档是CogView-4/GLM-Image)cogvideox-flash—— 免费文生视频 + 图生视频(图生视频名义支持、实测无效;付费档是CogVideoX-2)
换句话说,智谱的免费图像和视频生成,免费能调用的最新型号就这两个 Flash(文本另有免费的 GLM-4-Flash 系列,不在本文范围);更强的图像/视频旗舰款都得付费。这次我把这俩一起测了,并且照搬 Agnes 系列的同一套 benchmark 题横着比一遍:图片用同 8 题、视频用同 5 文生 + 3 图生,看国产免费的成色到底如何。这篇文章里每一张图、每一段视频都是我真跑 API 跑出来的,提示词照搬 Agnes 那两篇的经典 benchmark——只有这样,两边才比得公平。
太长不看(TL;DR)
不想看过程的,直接看结论。
一句话结论:除非你”完全不在意画质和效果、只在意免费 + 稳定 + 快”,否则别碰智谱这两个免费模型——在意画质的,看到这儿就可以关掉这篇、直接去用 Agnes(或其他付费模型)。下面是给”我就是只要免费”的人划的具体边界。
智谱这边能白嫖的就两个——cogview-3-flash(文生图)和 cogvideox-flash(文生视频 + 图生视频),同套题横评 Agnes 的结果:
图片档 cogview-3-flash
- ✅ 基线扎实:语义 / 构图 / 多主体 / 光影 / 手部解剖全过关(宇航员骑马、两猫下棋、逆光人像、双手捧杯都没崩)。
- ❌ 文字渲染不可靠、不分中英(最该知道的一点):英文要 “AGNES AI”,它写成了竖排的另一个词;中文「花好月圆」画成形似假字「火禾偕甡」、思维导图全是「苣厦紊衽」「醴藦」这种鬼画符。
- ❌ 不支持图生图:免费档只能文生图,没有 Agnes 那种换背景 / 风格迁移的编辑能力。
- ⚡ 快、不缩水:默认带水印(可关)、1024² 给满 1024²、均值 ~8.4s(Agnes ~24s,快近 3 倍)。
视频档 cogvideox-flash
- △ 文生视频内容保真过关、但画质明显逊于 Agnes:5 条核心元素全对、无多腿/变形硬伤;质感偏”塑料 / 发糊 / 细节差”,同题 Agnes 锐利写实、差一截(5 条里水下那条相对最好,也别当高质量看)。
- ❌ 图生视频主体锁定全崩:3 个场景 0/3 锁住——官方支持图生视频,但实测输出从第 1 帧就无视输入图(食物:竹蒸笼→木托盘、小笼包都变样;地铁青年:关键帧对、视频却漂成另一个人;窗台橘猫:关键帧还被 cogview 画跑题)。
- ⚡ 比 Agnes 快得多:5s 成片均值等 ~61s(约 12 倍);Agnes 1080p 3.4s 成片等 ~216s(约 64 倍),智谱耗时倍数约 Agnes 的 1/5。
- ✅ 接口更干净:
duration/resolution/fps,没 Agnes”帧数必须 8n+1”那个坑。
一个贯穿发现:cogview-3-flash 对”按指令落实指定内容”整体不可靠——文字渲染不分中英都崩,中文场景理解也崩(视频篇「橘猫坐窗台看雨」2/2 次画成”礼堂 / 花园女子”、根本没猫)。“把指定内容准确写出来 / 画出来”是免费 Flash 档的整体弱项。
所以怎么用:只图”免费 + 能跑 + 不限量”才考虑——做草稿、试水、批量出点不在意好看与否的素材,它能用、还快;但凡对画质 / 文字 / 一致性有点要求,直接上 Agnes 或其他付费模型。
下面是完整过程。
一、先认识智谱免费档:两个模型 + 鉴权怎么搞
Agnes 的鉴权很省心——标准 Authorization: Bearer <key>,完事。智谱多了一层”特色”,值得先说清楚,不然后面调接口(图、视频都一样)容易卡住。
两个免费模型速查
| 模型 | 类型 | 价格 | 上线 / 代际 | 本文用 |
|---|---|---|---|---|
cogview-3-flash | 文生图 | 免费 | 2024 年底上线(底座 CogView-3,2024 系列) | ✅ 图片篇 |
cogvideox-flash | 文生视频 + 图生视频(名义支持 / 实测无效) | 免费 | 2024 年底上线(底座 CogVideoX,2024-07「清影」同源) | ✅ 视频篇 |
cogview-4 / glm-image | 文生图(旗舰) | 付费 | 更新(付费档) | |
cogvideox-2 | 文生/图生视频 | 付费 | 更新(付费档) |
先把这俩免费模型的”代际”摆出来——都是 2024 年的底子。cogvideox-flash 背后是 2024 年 7 月发布的「清影」同源 CogVideoX(8 月开源 2B、9 月开源 5B 图生视频版、11 月升级到 1.5);cogview-3-flash 底座是 2024 年的 CogView-3 系列,是智谱首个免费文生图。两者都作为 2024 年底上线的”Flash 免费全家桶”(语言 GLM-4-Flash、视觉 GLM-4V-Flash、出图 CogView-3-Flash、出视频 CogVideoX-Flash)对外免费开放。
拿这个代际和开头的 Agnes 定档一对就有意思了:智谱视频是 2024 年代际,和 Agnes 视频(我判它 2024 年水平)正好同代——本以为”同一代的货、画质该差不多”,但实测 cogvideox 画质明显逊于 Agnes(塑料/发糊),说明代际不是画质的决定因素、免费档的阉割才是;图片这边,CogView-3 也是 2024 年的系列,比 Agnes 图片(2025 上半年)还旧半代,但实测基线(语义/构图/光影/手部)只比 Agnes 略逊一线、没被代际差拉开——真正露底的是文字渲染(中英都没按指令写对)——说明代际不是唯一因素,免费档的文字渲染阉割才是智谱图片真正的短板。
- 图片端点:
POST https://open.bigmodel.cn/api/paas/v4/images/generations - 视频端点:
POST https://open.bigmodel.cn/api/paas/v4/videos/generations(异步,先拿id,再轮询GET /async-result/{id}) - base_url 统一是
https://open.bigmodel.cn/api/paas/v4
鉴权:两种方式,图和视频通用
去 open.bigmodel.cn 注册(新用户有 token 赠送,具体额度以官网当时活动政策为准),API Key 长成 {id}.{secret} 的样子(点号前后两段)。它支持两种鉴权:
方式一:直接 Bearer(推荐,最简单)
新版 HTTP 接口直接把完整 API Key 当 Bearer token 用就行,和 Agnes 一样:
curl https://open.bigmodel.cn/api/paas/v4/images/generations \
-H "Authorization: Bearer $ZHIPU_API_KEY" \
-H "Content-Type: application/json" \
-d '{"model":"cogview-3-flash","prompt":"...","size":"1024x1024"}'方式二:JWT(智谱特色,旧版/高级用法)
把 {id}.{secret} 拆开,用 HS256 签一个 JWT,注意 exp 和 timestamp 都是毫秒级时间戳,header 里还要带 sign_type: SIGN:
import time, jwt
api_key = "你的 id.你的 secret"
aid, secret = api_key.split(".", 1)
ms = int(round(time.time() * 1000))
token = jwt.encode(
{"api_key": aid, "exp": ms + 3600*1000, "timestamp": ms},
secret, algorithm="HS256",
headers={"alg": "HS256", "sign_type": "SIGN"})
# 然后 Authorization: Bearer <token>两种都行,本文所有请求默认走方式一(直接 Bearer)。官方鉴权文档在 docs.bigmodel.cn/cn/guide/develop/http/introduction。
一个小坑:JWT 那套的 exp 是毫秒不是秒,且不能超过 7 天;用错单位会签出一个”立即过期”的 token,请求直接 401。
二、图片实测:CogView-3-Flash 八道经典 benchmark 逐题过
我照搬 Agnes 图片篇的 8 道文生图题,覆盖语义合成、英文文字渲染、中文多物体组合、中文海报、中文结构化图、风格光影、复杂场景、解剖结构。每张图都用外部视觉模型逐项检查(认字、数数、主体对不对),中文题还逐字辨认了图上的汉字。所有图都用 watermark: false 生成(去水印)。
第一题:宇航员骑马(文生图经典 benchmark)
文生图的”Hello World”,测主体组合 + 空间关系——宇航员得真的”骑”在马背上。
| cogview-3-flash(智谱,9.7s) | agnes-image-2.1-flash (Agnes, 30.0s) |
|---|---|
 |  |
视觉模型检查:✅ 两边都通过,Agnes 略胜一筹。cogview:宇航员正确骑在马背上(双腿跨立、踩镫、姿态合理),火星红土沙漠 + 星空、电影感光影到位,人与马解剖均正常。Agnes:骑棕马、姿态正确,宇航服还带了国旗/任务徽章、天空挂着多个月亮——画面元素更丰富、构图张力稍强。
第二题:霓虹灯招牌写 “AGNES AI”(英文文字渲染)
文字渲染是文生图公认难点,绝大多数模型碰到”指定文字”就崩。
| cogview-3-flash(智谱,8.9s) | agnes-image-2.1-flash (Agnes, 29.2s) |
|---|---|
 |  |
视觉模型逐字母辨认:❌ cogview 没写出指定文字。prompt 明确要求招牌写 “AGNES AI”,cogview 却生成了一根竖排的粉色霓虹招牌、上面是另一个词(视觉模型一次读作 “ELECTRIC”、一次读作 “LIFE”,两次读法不一致,说明那串字母本身也不太规整)——根本不是 “AGNES AI”。换句话说:它能画出干净、可读的英文字母(不像中文那样出形似假字),但不按 prompt 写指定的词,自己另造了一个。
对比 Agnes:同一个 prompt,Agnes 把 “AGNES / AI” 两行逐字母全对写了出来。这一题,指定文字渲染 Agnes 完胜、cogview 没过关。
第三题:两只橘猫下棋(中文 + 多物体组合)
一次测三个能力:中文 prompt 遵循、多主体数量(两只猫)、复杂场景(棋盘 + 霓虹 + 雨夜)。
| cogview-3-flash(智谱,8.3s) | agnes-image-2.1-flash (Agnes, 26.7s) |
|---|---|
 |  |
视觉模型检查:✅ 两边都通过,Agnes 略胜一筹。正好两只橘猫隔棋盘对弈,棋子齐全,赛博朋克霓虹雨夜到位,中文 prompt 遵循得很好。Agnes 那张一只猫正伸爪走子、湿漉漉的毛发细节也更足——生动度稍高。
宇航员、两只猫这两题,加上后面的逆光人像、双手捧杯——cogview-3-flash 的基线很扎实,语义/构图/多主体/光影/解剖都过关。但一碰上”按指令把指定文字写进图”就露怯:第二题连英文指定词 “AGNES AI” 都没写对(见上),下一题更狠——把中文汉字直接”画”进图里。
第四题:中秋促销海报(中文文字渲染——海报场景)
提示词:中秋促销海报,深蓝色夜空一轮圆月……主标题大字「花好月圆」四个汉字居中放大,副标题「中秋特惠 全场八折」……。
| cogview-3-flash(智谱,8.6s) | agnes-image-2.1-flash (Agnes, 20.0s) |
|---|---|
 |  |
视觉模型逐字辨认:❌ 崩了。要求的主标题「花好月圆」,cogview-3-flash 画成了「火禾偕甡」——每个字都和目标字”形似但不是”,是典型的中文渲染翻车(画出一堆笔画像、但根本不是那个字的假字)。副标题也模糊难辨。
对比 Agnes:同一个 prompt,Agnes 把主标题「花好月圆」、副标题「中秋特惠 全场八折」12 个汉字全部画对,一字不差。这一题,智谱免费档完败给 Agnes。
第五题:「时间管理」中文思维导图(中文文字渲染——结构化图)
比海报更狠:1 个中心节点 + 4 个分支节点(4×4=16 字)+ 4 段说明小字,文字分散排布,越分散越易崩。
| cogview-3-flash(智谱,8.0s) | agnes-image-2.1-flash (Agnes, 14.0s) |
|---|---|
 | 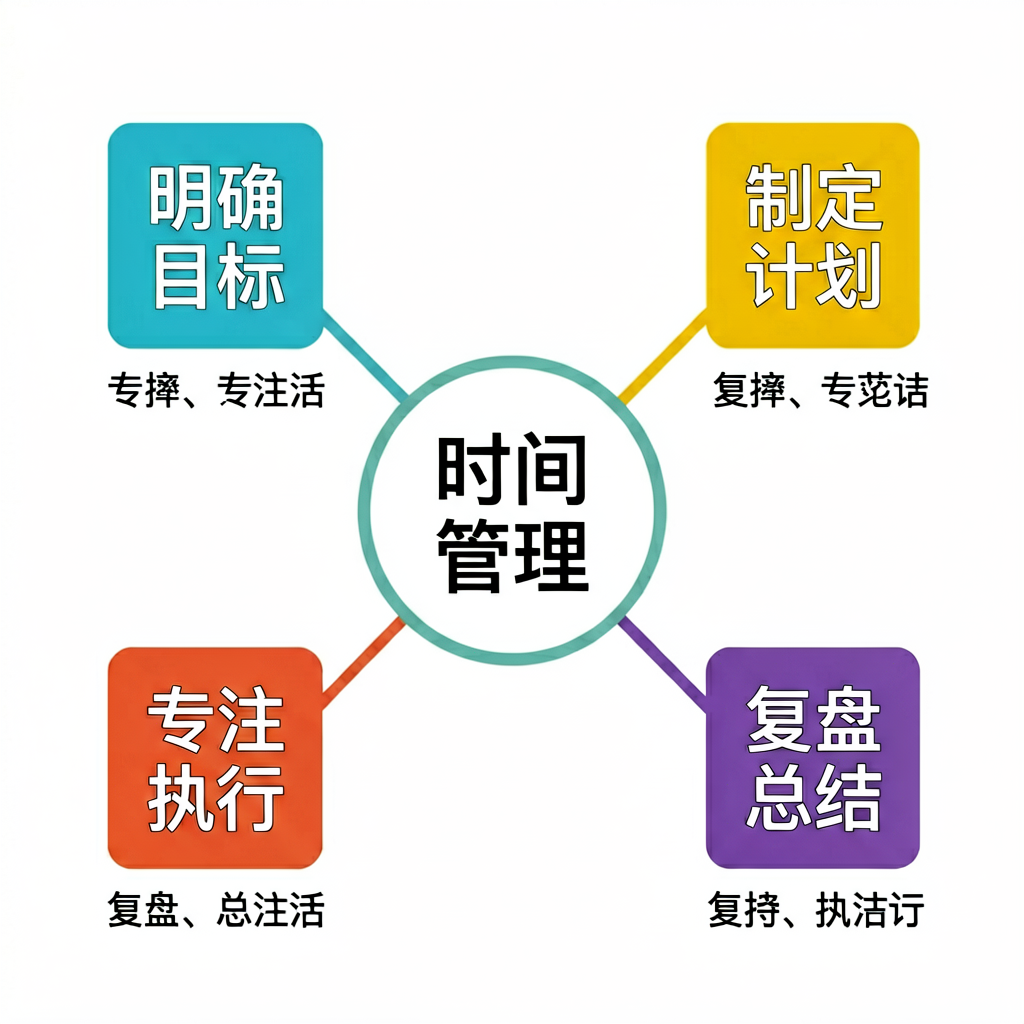 |
视觉模型逐字辨认:❌ 全崩。中心要求「时间管理」,cogview-3-flash 画成「苣厦紊衽」;四个分支要求「明确目标/制定计划/专注执行/复盘总结」,实际是「麥監」「醴藦」「叛鹩」这种——全是形似假字、毫无语义,密集小字崩得最狠。
对比 Agnes:Agnes 中心「时间管理」对、四个分支名 16 字全对,只有方块下的密集小字说明崩了。也就是说——Agnes 在这道题是”标题全对、小字崩”,智谱是”连标题都全崩”,差距很明显。
一个反直觉的点:智谱是中国厂商,Agnes 是新加坡厂商,但在这套中文渲染题上,智谱的免费 Flash 档反而输给 Agnes。这不是说智谱中文能力不行——它的付费档 CogView-4 / GLM-Image 中文渲染 reportedly 强很多,只是免费 Flash 档确实弱。免费的天花板,在这里露了底。
第六题:渔夫逆光人像(风格 + 光影控制力)
测对”逆光 / 边缘光 / 黄金时刻 / 景深虚化”这些抽象美学描述的遵循度。
| cogview-3-flash(智谱,8.2s) | agnes-image-2.1-flash (Agnes, 28.6s) |
|---|---|
 |  |
视觉模型检查:✅ 两边都通过,Agnes 略胜一筹。两边都有明确的方向性暖色边缘光勾出脸、发、胡须轮廓,背景浅景深 bokeh 虚化,非平光;但 Agnes 的皮肤/胡须质感更扎实、几乎无 cogview 那种轻微”塑料感”——写实度稍高。
第七题:俯拍 6 人晚宴(复杂场景精确数量)
提示词要求 exactly 6 plates, 6 forks, 6 knives, 6 wine glasses + 中央火鸡,专压精确数量遵循(DPG-Bench 题型)。
| cogview-3-flash(智谱,7.6s) | agnes-image-2.1-flash (Agnes, 22.0s) |
|---|---|
 |  |
视觉模型检查:△ 两边都没过精确数量。cogview:火鸡居中 ✓,但只摆出约 4 个座位、餐具数(盘 11、叉 8、刀 8、杯 4)全偏离要求的 6;Agnes:火鸡居中 ✓,同样只有约 4 个座位、餐具(盘 4、叉 8、刀 4、杯 4)也不对。两边都没坐满 6 人、餐具精确数量也都没对上,难分高下——精确数量遵循是免费档内的常见问题,智谱和 Agnes 都没解决。
第八题:两只手捧咖啡杯(解剖结构——手部)
手部是 AI 生图公认难点(多指、缺指常翻车)。这题正面硬压,要求”十根手指清晰可见”。
| cogview-3-flash(智谱,8.0s) | agnes-image-2.1-flash (Agnes, 22.5s) |
|---|---|
 |  |
视觉模型逐指数数:✅ 两边都通过,Agnes 略胜一筹。cogview:两手捧杯,解剖正确、无多指无并指无畸形,可见 8 指、另 2 指被杯体自然遮挡(合理,不算缺指)。Agnes:可见 9 指、解剖同样正常——题目要”十指清晰可见”,Agnes 更贴近要求。
图片小结 + 耗时
8 道题汇总(n=1,首跑):
| 维度 | cogview-3-flash | 对比 Agnes 2.1 |
|---|---|---|
| 语义合成 / 多主体 | ✅ 过关 | Agnes 略胜(细节更丰富) |
| 英文文字渲染 | ❌ 字母干净但不按指令(要 AGNES AI、写成他词) | Agnes 胜(AGNES AI 全对) |
| 中文文字渲染(海报) | ❌ 崩(花好月圆→火禾偕甡) | Agnes 完胜(12 字全对) |
| 中文文字渲染(思维导图) | ❌ 全崩 | Agnes 胜(标题全对、仅小字崩) |
| 风格 / 光影控制 | ✅ 过关 | Agnes 略胜(写实度更高) |
| 复杂场景精确数量 | △ 火鸡对、餐具数不对 | 都失准(两边都没坐满 6 人) |
| 手部解剖 | ✅ 无畸形 | Agnes 略胜(可见指更多) |
耗时(服务端生成时间,1024×1024,单张):
| 测试 | cogview-3-flash | agnes-image-2.1-flash |
|---|---|---|
| 宇航员骑马 | 9.7s | 30.0s |
| 文字渲染 “AGNES AI” | 8.9s | 29.2s |
| 两只橘猫下棋 | 8.3s | 26.7s |
| 中秋海报 | 8.6s | 20.0s |
| 思维导图 | 8.0s | 14.0s |
| 渔夫逆光人像 | 8.2s | 28.6s |
| 俯拍晚宴 | 7.6s | 22.0s |
| 双手捧杯 | 8.0s | 22.5s |
| 均值 | ≈8.4s | ≈24.1s |
比 Agnes 快了将近 3 倍(均值 8.4s vs Agnes 24.1s)。尺寸方面,请求 1024×1024 实际就给满 1024×1024,不缩水——这点比 Agnes 厚道(Agnes 横版请求 1920×1088 实际只给 1312×736)。
图片档还有两个特点:文字渲染硬伤 + 水印
文字渲染:免费档的硬伤(不分中英)。 这是 cogview-3-flash 最突出的短板。中文:海报「花好月圆」画成「火禾偕甡」、思维导图全是「苣厦紊衽」——不是画得丑,是画出来的根本不是那个字,是一堆笔画相似、但谁也读不通的假字。英文:能画出干净字母,但不按 prompt 写指定词——要 “AGNES AI”,它写成了竖排的另一个词(第二题)。一句话:cogview-3-flash 没法可靠地”按指令把指定文字写进图”,中英都一样。 为什么一个国产模型的文字渲染反而不如新加坡的 Agnes?我的判断是:这不是”中文能力”的问题,是”免费档型号”的问题——智谱的文字渲染能力都堆在付费的 CogView-4 / GLM-Image 上,免费的 Flash 是轻量快出图模型,文字渲染不是它的设计目标。
水印:默认带,但能去掉。 cogview-3-flash 默认 watermark: true,返回的图带显式 + 隐式数字水印(URL 文件名里能看到 _watermark 标识)。去水印加一个参数:
{"model": "cogview-3-flash", "prompt": "...", "size": "1024x1024", "watermark": false}前置条件:得先在智谱控制台「个人中心 → 安全管理 → 去水印管理」签一份免责声明,watermark: false 才生效。这点和 Agnes 不同——Agnes 免费档出图不带水印,智谱默认带、需主动关。
三、视频实测:CogVideoX-Flash 文生 5 条 + 图生 3 条
图片测完,自然轮到视频。智谱免费视频模型就 cogvideox-flash 一个(文生 + 图生),官方还挂了不少卖点——支持 4K、60fps、最长 10 秒、AI 音效。我照搬 Agnes 视频篇的同一套 VBench 类题,逐条抽中间帧用视觉模型核对。单帧只能判内容保真 + 画质,判不了运动流畅度(那得点开 mp4 看)。
3.1 文生视频:5 条逐题实测
5 条文生视频(duration=5,默认分辨率/帧率交给服务端)。
1. 单主体运动 · 橘猫海滩走(VBench 经典运动项)
提示词:A fluffy orange cat walking along a beach at sunset, gentle waves in the background, cinematic, slow motion
| cogvideox-flash(智谱) | agnes-video-v2.0(Agnes) |
|---|---|
 |  |
视觉复核:✅ 内容对——橘猫、日落海滩、海浪都在,四腿解剖正常;但画质偏”塑料感/毛发缺细节/边缘发糊”,典型 AI 生成的梦境感。对比右图 Agnes:同题 Agnes 的锐度、毛发质感明显更扎实,差距一眼可见。
2. 复杂多动态 · 夜间城市航拍(VBench 多动态元素)
提示词:Aerial drone shot of a busy city intersection at night, cars with headlights moving, neon signs, rain on the streets
| cogvideox-flash(智谱) | agnes-video-v2.0(Agnes) |
|---|---|
 |  |
视觉复核:✅ 内容对——航拍、车灯轨迹、霓虹、湿街反光都在;招牌文字全乱码(预期内,cogview 系文字渲染弱,上节已证);画风偏数字艺术、不写实。对比右图 Agnes:Agnes 画面更干净锐利,智谱明显更糊。
3. 运镜控制 · 科幻走廊推镜头(VBench camera motion)
提示词:Dolly zoom shot moving forward through a long futuristic corridor with glowing blue lights, camera continuously pushing in, dramatic perspective, cinematic
| cogvideox-flash(智谱) | agnes-video-v2.0(Agnes) |
|---|---|
 |  |
视觉复核:✅ 内容对——未来感走廊、蓝色发光、强透视纵深汇聚点正确(单帧判不了镜头是否真”持续前推”,点 mp4 看);画质偏绘画感。对比右图 Agnes:Agnes 光效和质感更扎实。
4. 特殊场景 · 水下海龟(流体渲染)
提示词:Underwater scene, a sea turtle swimming over a coral reef, sun rays filtering through the water surface, schools of fish, cinematic, slow motion
| cogvideox-flash(智谱) | agnes-video-v2.0(Agnes) |
|---|---|
 |  |
视觉复核:✅ 内容对——海龟/珊瑚/鱼群/阳光光束都在,是 cogvideox 5 条里质感相对最好的一条(水质没那么塑料)。但别误会成”高质量”——对比右图 Agnes:Agnes 的海龟壳纹、珊瑚细节、水体通透感都更胜一筹,智谱这条只是”矮子里拔将军”。
5. 复杂场景 · 夜市街道
提示词:A night market street with food stalls, steam rising from dumplings, people walking, lanterns swaying, cinematic, 4k
| cogvideox-flash(智谱) | agnes-video-v2.0(Agnes) |
|---|---|
 |  |
视觉复核:✅ 内容对——灯笼/食物摊/蒸汽/行人都在,氛围对;但整体发糊、印象派、无清晰可读招牌。对比右图 Agnes:Agnes 细节和清晰度明显更好(注:Agnes 这条成片更长,6.7s)。
文生视频小结:5/5 内容保真全部过关、无硬伤(多腿/变形这类结构硬伤都没有)。但画质整体明显逊于 Agnes——cogvideox 普遍偏”塑料感/发糊/毛发与纹理缺细节”,5 条里只有 underwater_turtle 质感稍好;同题并排对比 Agnes,Agnes 在锐度、纹理细节、写实感上都明显更高。之前若给人”两边大体同档”的印象,那是错的——质感差着一截,cogvideox 明显落后 Agnes,不是一个档次。
3.2 图生视频:cogview 关键帧 + cogvideox,锁不住人
文生视频救不了角色一致(和 Agnes 一样,每次生成都不一样)。业界标准解法是”关键帧 + 图生视频首帧锁定”——先用文生图锁主体,再让它接着动。智谱这条链是 cogview-3-flash 出关键帧 → cogvideox-flash 以关键帧为首帧生成视频。3 个场景测下来,一个都没锁住(0/3)。
1. 食物 · 夜市小笼包(❌ 没锁住)
| 关键帧(cogview) | 图生视频(cogvideox) |
|---|---|
 |  |
关键帧正确(小笼包在竹蒸笼里、白白胖胖带褶子 + 蒸汽 + 暖灯笼光)。但图生视频从第 1 帧起就完全是另一副样子——小笼包的形状、摆放都对不上关键帧,还从竹蒸笼跑到了木托盘上、蒸笼整个不见了。cogvideox 没保住输入图、等于无视关键帧按文本另画了一段,一致度”低”。
2. 人物 · 地铁青年(❌ 漂成另一个人)
| 关键帧(cogview) | 图生视频(cogvideox) |
|---|---|
 |  |
关键帧正确(青年 + 浅色衬衫 + 地铁车厢 + 蓝座椅)。但图生视频中间帧变成了另一个人(短深色头发、深色衣服)、另一个场景(昏暗室内/酒吧,根本不是地铁)——cogvideox 图生视频没锁住主体,人和场景都漂了,一致度”低”。
3. 动物 · 窗台橘猫(❌ 关键帧就跑题)
| 关键帧(cogview) | 图生视频(cogvideox) |
|---|---|
 |  |
关键帧 prompt「橘猫坐窗台看雨」,cogview 两次生成都没出猫:第一次给了一个”阶梯木台 + 人群的礼堂”,重跑一次变成了”花园里的年轻女子”——cogview-3-flash 对这条中文场景 prompt 的理解完全跑题(2/2 次无猫)。图生视频中间帧里出现的则是一只灰猫。这条链从关键帧阶段就崩了,一致度”低”。
图生视频小结:3 个场景全军覆没、0/3 主体被稳定锁定。两个环节都暴露问题:
- cogview 关键帧不稳——cat 场景中文 prompt「橘猫坐窗台看雨」2/2 次完全跑题(这是下一节”贯穿发现”要展开的)。
- cogvideox 图生视频根本锁不住主体——food 关键帧明明正确(竹蒸笼小笼包),图生视频从第 1 帧就把它改成了木托盘上的另一副样子、蒸笼都没了;man 关键帧也正确,照样漂成另一个人/另一个场景。连食物特写这种最简单的主体都保不住。
更深一层:cogvideox-flash 官方是支持图生视频的(文档列了 image 参数、模型能力含图生视频),脚本也确实把 image 传进了请求、API 正常返回视频。但实测 3 条输出从第 1 帧起就完全无视输入图、只按文本 prompt 另生成——等于这个图生视频功能”名义上有、实际不工作”,输入图基本是个摆设。
对比 Agnes 图生视频:Agnes 视频篇同套 3 场景 3/3 主体一致度”高”(窗台橘猫、地铁青年、夜市小笼包全锁住)。智谱本批 0/3,图生视频主体锁定能力明显弱于 Agnes。
顺带一个比 Agnes 友好的点:智谱 cogvideox 的 image 参数同时接受 URL 和本地文件/base64;Agnes 的图生视频只接受 http(s) URL,本地图得先传到公网。对接上智谱这点更省事。
3.3 视频耗时:12 倍定律(智谱比 Agnes 快得多)
视频接口是异步的:先 POST /videos/generations 创建任务拿 id,轮询 GET /async-result/{id} 看 task_status,等 SUCCESS 后从 video_result[0].url 拿下载链接(还有个 cover_image_url 封面)。
文生视频 5 条(服务端生成耗时;智谱成片均 5s,Agnes 成片 3.4s、夜市那条 6.7s):
| id | cogvideox-flash | agnes-video-v2.0 |
|---|---|---|
| cat_walking_beach | 52.6s | 235.2s |
| city_traffic_aerial | 62.7s | 203.3s |
| dolly_zoom_corridor | 63.0s | 190.0s |
| underwater_turtle | 62.6s | 237.5s |
| night_market_street | 63.1s | 351.5s |
| 均值 | ≈60.8s | ≈243.5s |
智谱视频生成快得多——均值 60.8s vs Agnes 243.5s,绝对耗时约为 Agnes 的 1/4、单条快 3–4 倍。若按”耗时 ÷ 成片时长”算倍数:智谱约 12 倍、Agnes 约 60 倍(前 4 条 81 帧短片),智谱的耗时倍数约为 Agnes 的 1/5。这是智谱视频档相对 Agnes 几乎唯一的优势——快(画质和主体锁定都明显输,见上下文)。
智谱 vs Agnes 视频接口差异(给要自己调 API 的人)
| 维度 | 智谱 cogvideox-flash | Agnes agnes-video-v2.0 |
|---|---|---|
| 参数体系 | duration(秒) / resolution / fps | num_frames(8n+1) / frame_rate / width / height |
| 帧数坑 | 无 | 必须 8n+1(81/121/161/241/441) |
| 创建端点 | POST /videos/generations → 拿 id | POST /videos → 拿 video_id |
| 轮询端点 | GET /async-result/{id}(在 /v4 下) | GET /agnesapi?video_id=(不在 /v1 下) |
| 状态值 | SUCCESS / PROCESSING / FAIL | completed / queued / in_progress / failed |
| 下载字段 | video_result[0].url(直觉) | remixed_from_video_id(坑爹,不是 video_url) |
| 图生视频 image 参数 | URL 或 本地/base64 | 只 URL |
| 单条耗时 | ~61s(5s 成片,≈12 倍) | ~216s(3.4s 成片,≈64 倍) |
一句话:智谱视频接口设计更干净、字段更直觉、还没 Agnes 那几个反直觉的坑;代价是图生视频主体锁定能力弱。
四、限流:官方只卡”并发数”(图、视频都一样)
Agnes 那两篇我花了一大节实测并发——因为 Agnes 官方对限流只字不提,只能自己压。智谱这边省事多了:官方有公开的速率限制文档(docs.bigmodel.cn/cn/api/rate-limit),规则写得很清楚,我直接引,不重复造轮子压测。规则对 cogview-3-flash 和 cogvideox-flash 一致(都是只卡并发、不卡日用量;具体并发数因模型和等级而异,见下表):
- 限流维度是”并发请求数”——即”同一时刻正在处理中的请求数量”,不是 QPS(每秒请求数)、也不是每日调用次数。
- Flash 系列免费模型(含 cogview-3-flash、cogvideox-flash)不设每日调用上限、不设 QPS 硬上限,只限制同时并发数。
- 并发上限按账户的积分等级(V0–V3)分配,图、视频两个模型独立计算;免费用户默认是 V0。
- 高峰期(工作日白天、每天 15–18)会有动态限流。
- 撞到限流返回错误码 1302(并发达上限,降并发/排队/重试);平台整体过载返回 1305(稍后重试)。
各等级并发上限(官方文档口径):
| 积分等级 | 门槛(累计消费) | cogview-3-flash(图) | cogvideox-flash(视频) |
|---|---|---|---|
| V0 | 默认(免费) | 1 | 3 |
| V1 | 满 2000 | 20 | 5 |
| V2 | 满 10000 | 30 | 10 |
| V3 | 满 50000 | 40 | 15 |
重点看 V0:免费档图片并发只有 1 路——批量出图得一张一张排队,挺慢;视频 3 路稍宽裕。要拉高并发只能靠累计消费升等级(V1 要消费满 2000),那就基本脱离”纯免费”了;订阅 GLM Coding Plan(Lite/Pro/Max)是另一条提权路径,具体以控制台「速率限制」页为准。
翻译成大白话:智谱免费档不会因为你”今天调太多”把你封了,也不会卡你”每秒只能发几个”——它只管”你同时能开几路”。但免费 V0 这几路很少(图 1 / 视频 3):稳定是真稳定,吞吐很低也是真低,批量出图基本得排队、配合重试能跑但快不起来。比起 Agnes 那种”官方不说、全靠压测才知道瓶颈”,智谱这点透明得多。本次图片 8 张 + 视频 8 条(含重跑)都没撞限流。
五、贯穿发现:文字渲染不分中英都崩,中文场景理解也不稳
把图片篇和视频篇合到一起看,有两个比单个结论更值得注意的发现:
发现一:文字渲染不分中英,都不按指令。 cogview-3-flash 一碰上”把指定文字写进图”就不可靠——英文 prompt 要 “AGNES AI”,它写成了竖排的另一个词(第二题);中文要「花好月圆」,画成形似假字「火禾偕甡」(第四题)。差别只在失败形态:英文还能写出干净字母、只是词不对;中文连字都画不对,直接一堆形似假字。
发现二:中文场景理解也不稳。 视频篇里要求关键帧「橘猫坐窗台看雨」,cogview 两次跑题——一次给”阶梯木台 + 人群的礼堂”,一次给”花园里的年轻女子”,2/2 次画面里根本没有猫。
两件事合起来意味着:cogview-3-flash 对”按指令把特定内容(文字、场景)准确落实”这件事整体不可靠。这又进一步波及视频链路——用智谱免费档做”中文 prompt → cogview 关键帧 → cogvideox 视频”这条图生视频链,关键帧阶段就可能跑题,整条链的可靠性打折(视频篇的窗台橘猫正是这么崩的)。
为什么”国产模型反而中文弱、连英文指定词也写不对”?和图片篇的判断一致:这不是”能力”的问题,是”免费 Flash 档”的问题——智谱的强能力大概率堆在付费的 CogView-4 / GLM-Image 上,免费的 Flash 档是轻量快出图模型,文字渲染和精细场景遵循本来就不是它的设计目标。免费的代价,在这里很具体。
六、综合总结:到底什么水平,免费用在哪
把 cogview-3-flash 和 cogvideox-flash 和 Agnes 用同一套题横着比完,结论可以给得很具体了。
横评总表
| 维度 | cogview-3-flash(智谱图) | agnes-image-2.1-flash |
|---|---|---|
| 语义/构图/多主体/光影/手部 | ✅ 过关 | ✅ 过关(Agnes 略胜) |
| 英文文字渲染 | ❌ 字母干净但不按指令写指定词 | ✅ AGNES AI 全对(Agnes 胜) |
| 中文文字渲染 | ❌ 崩 | ✅ 标题全对(Agnes 胜) |
| 图生图编辑 | ❌ 不支持 | ✅ 换背景/风格迁移(Agnes 胜) |
| 出图速度 | ~8.4s/张(智谱胜,快近 3 倍) | ~24s/张 |
| 尺寸 | 不缩水(智谱胜) | 按档缩水 |
| 水印 | 默认带(可关) | 无水印(Agnes 胜) |
| 维度 | cogvideox-flash(智谱视频) | agnes-video-v2.0 |
|---|---|---|
| 文生视频内容保真 | ✅ 5/5 过关 | ✅ 5/5 过关(打平) |
| 文生视频画质/质感 | ❌ 塑料感/发糊、细节差 | ✅ 锐利写实(Agnes 胜) |
| 图生视频主体锁定 | ❌ 0/3(实际无视输入图) | ✅ 3/3 高一致(Agnes 胜) |
| 出片速度 | ~61s/5s 成片(智谱胜,快 3–4 倍) | ~216s/3.4s |
| 接口干净度 | 字段直觉、无帧数坑(智谱胜) | 帧数 8n+1、下载字段坑爹 |
| 限流透明度 | 官方公开规则(智谱胜) | 官方不公开,靠压测 |
那我到底用不用
一句话先给:除非你”完全不在意质感和效果、只在意免费 + 稳定 + 快”,否则这两个免费模型都不建议碰——Agnes 免费档(或其他付费模型)在画质、文字、图生视频一致性上全面更好。下面是给”我就是只要免费”的人划的具体边界。
图片档 cogview-3-flash——只在”不写文字、也不在意比 Agnes 略糙”时凑合用:
- ✅ 勉强适合:不写任何指定文字的写实场景图、插画、PPT 配图、批量出草稿——能用、快、免费、不缩水(但画质仍略逊 Agnes)。
- ❌ 别用:招牌/海报/思维导图/带标题的图(中英文指定文字都写不对);需要换背景/风格迁移的图生图(不支持)。
视频档 cogvideox-flash——画质短板比图片更明显,更得”只图免费”才用:
- ✅ 勉强适合:单条简单场景素材、对画质和主体一致性都没要求、只要”免费 + 快”地出个能动的片。
- ❌ 别用:在意画质/质感(明显逊于 Agnes,偏塑料/发糊);多镜头剧情、角色一致(图生视频锁不住人,0/3 成功率);关键帧依赖中文场景理解的链路(cogview 中文不稳,可能从第一步就跑题)。
关于”免费”本身
智谱把 GLM-4-Flash、CogView-3-Flash、CogVideoX-Flash 这一整档都设成永久免费、且只卡并发不卡日用量,对个人开发者是真友好——视频档还开放了 4K/60fps/10s/AI 音效。但别误会”友好 = 好用”:免费 V0 档图片并发才 1、视频 3(见上节限流表),吞吐很低、批量得排队——“免费”是真免费,“能跑多快”是另一回事。但免费的代价也实在:图像这边文字渲染(中英都算)和图生图编辑阉割过、视频这边画质明显逊于 Agnes + 图生视频主体锁定弱(0/3)+ cogview 中文场景理解不稳,强能力大概率都在付费档。免费拿来试水、做草稿、跑实验、出点不在意画质的素材,没问题;但凡对画质/文字/一致性有点要求,还是得上 Agnes 或其他付费模型。一句话:只有”完全不在意质感、只在意免费稳定”时,智谱免费档才轮得到上场;否则别考虑。
和 Agnes 那两篇一样的收获:用同一套标准 benchmark 把工具认真测一遍,比凭一两次印象下结论靠谱得多。 尤其是中文这种”国产模型理应更强”的预期,不实测你不会知道——智谱的免费 Flash 档,恰恰在中文(文字 + 场景)上露了底,图生视频一致性也输给了 Agnes,连视频画质都被 Agnes 甩了一截。预期是一回事,实测是另一回事。