【论文阅读笔记】Semantic Instance Segmentation with a Discriminative Loss Function
2 min
带有歧视的损失函数的语义实体分割(Semantic Instance Segmentation with a Discriminative Loss Function)
论文提出一种将特征空间的点分簇的损失函数,损失函数主要分为三项构成,分别为方差项(variance term),距离项(distance term),正则项(regulariztion trem),其中方差项计算的是簇内的距离,距离项计算的是簇与簇的距离,分别控制同簇点与簇中心之间的距离在δv之内,不同簇与簇的中心距离大于δd,论文下载地址
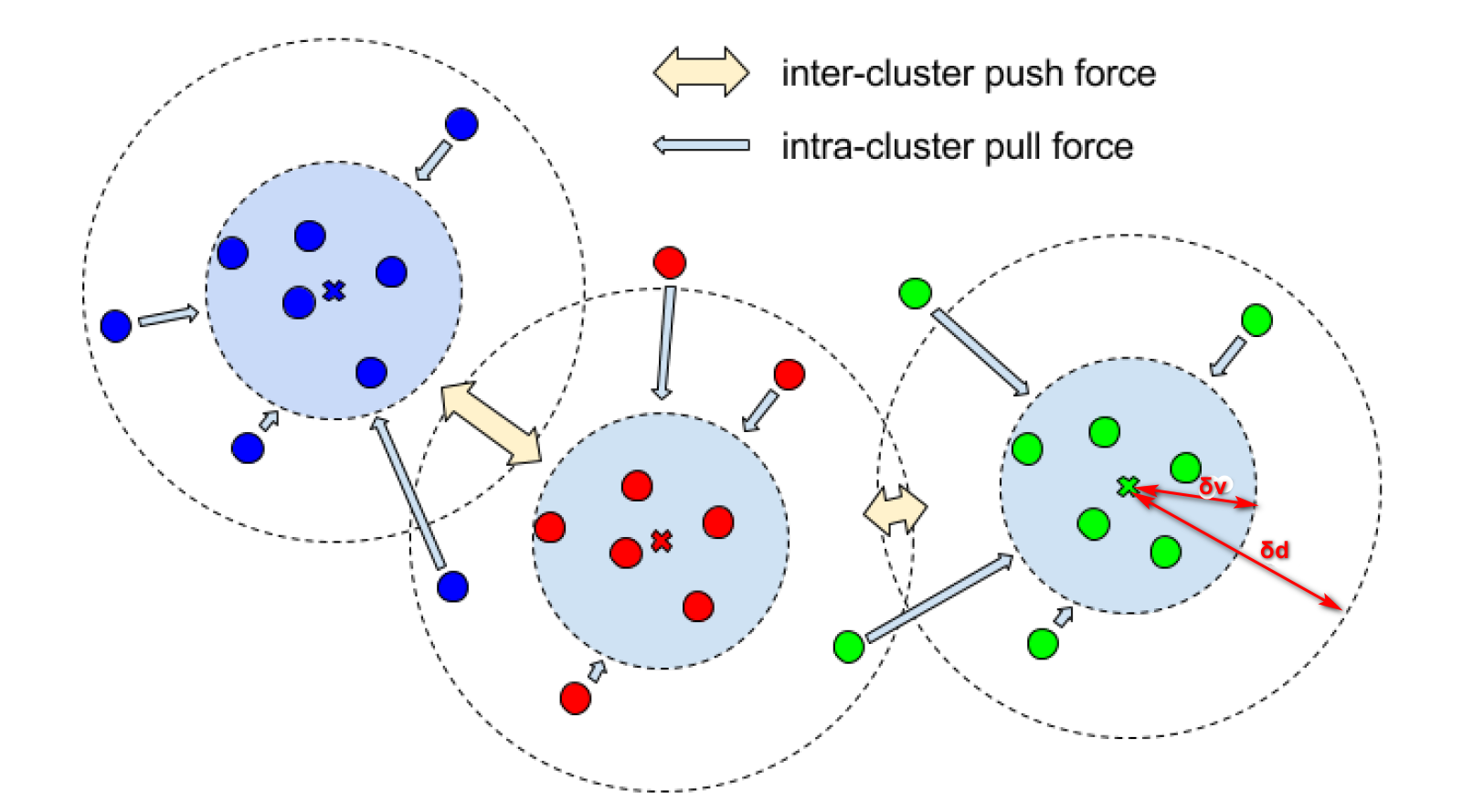
论文主要关注于损失函数,主要关注于训练出好的特征空间(如Embedding Space)。
带有歧视的损失函数
定义
是真实值中的簇的总数,簇中的元素数量,是一个元素对应的嵌入向量,是簇中嵌入向量的平均值(簇的中心),是 L1 距离或者 L2 距离,是 max(0,x) 定义的铰链函数,和代表方差和距离损失的间隙。
方差项
距离项
正则项
完整损失函数
在实验时,作者设置,。
其他内容
论文还说到了后处理(post-processing),包括增强鲁棒性(increasing robustness)等等,还有其他实验的设置和数据集,还有优缺点等等,这里最后说一下这个方法的优缺点(pros and cons)。
优缺点
论文中方法,在有重叠部分的情况下依然有好的效果,比如在合成的零散的线条中,在数据集图片中有比较相似的实例时,效果也比较好,但是,在随机多种多样的数据集中,效果不太好,在只有一个的实例对象的图片中训练效果不是太好。