【实践记录】faster-whisper VAD 漏句排查记:三次反转与一个错误的 benchmark
踩坑起因
使用 faster-whisper 的 BatchedInferencePipeline 对视频做批量转录生成字幕时,发现生成的字幕存在明显遗漏——视频中明明有语音,对应位置却没有字幕。
第一步:发现漏句,怀疑 VAD
检查后发现问题出在 BatchedInferencePipeline 默认启用的 VAD(Voice Activity Detection,语音活动检测)。VAD 的作用是检测哪里有人声、跳过静音片段、把音频切成小段以提高处理效率。初步怀疑是 VAD 将部分有语音的片段误判为静音并跳过,导致字幕缺失。
以下是视频转录后多处漏句的截图:

多段有声音的片段被跳过,生成的字幕不完整。对于字幕生成这种对准确性要求高的场景,漏句是不可接受的。
第二步:尝试关闭 VAD,遇到报错
既然怀疑 VAD,最直接的想法就是关闭它——给 BatchedInferencePipeline 传 vad_filter=False:
from faster_whisper import BatchedInferencePipeline
pipeline = BatchedInferencePipeline(model=model)
segments, info = pipeline.transcribe(
audio_path,
vad_filter=False,
batch_size=8,
language="zh",
)但运行后直接报错了。原因是 BatchedInferencePipeline 的核心逻辑是先把音频切成多个片段,再批量送进模型推理,默认依赖 VAD 来完成切段。关闭 VAD 后,它就不知道该如何拆分长音频。
当 vad_filter=False,且音频长度超过 chunk_length,又没有提供 clip_timestamps 时,程序会直接报错,提示需要开启 VAD 或提供 clip_timestamps:

也就是说,BatchedInferencePipeline 可以关闭 VAD(短音频没问题),但长音频关闭 VAD 后必须手动提供切段时间,很不方便。
第三步:改用 model.transcribe(能解决,但慢)
查看 GitHub issue faster-whisper#954 后,改用普通的 model.transcribe:
segments, info = model.transcribe(
audio_path,
vad_filter=False,
language="zh",
beam_size=5,
best_of=5,
initial_prompt=initial_prompt,
)改用后之前漏句的位置确实都恢复了:

但这也意味着放弃了 BatchedInferencePipeline 的批量推理速度优势。为了确认 VAD 漏句与 batch size 的关系,测试了同一段视频在不同配置下的转录结果:
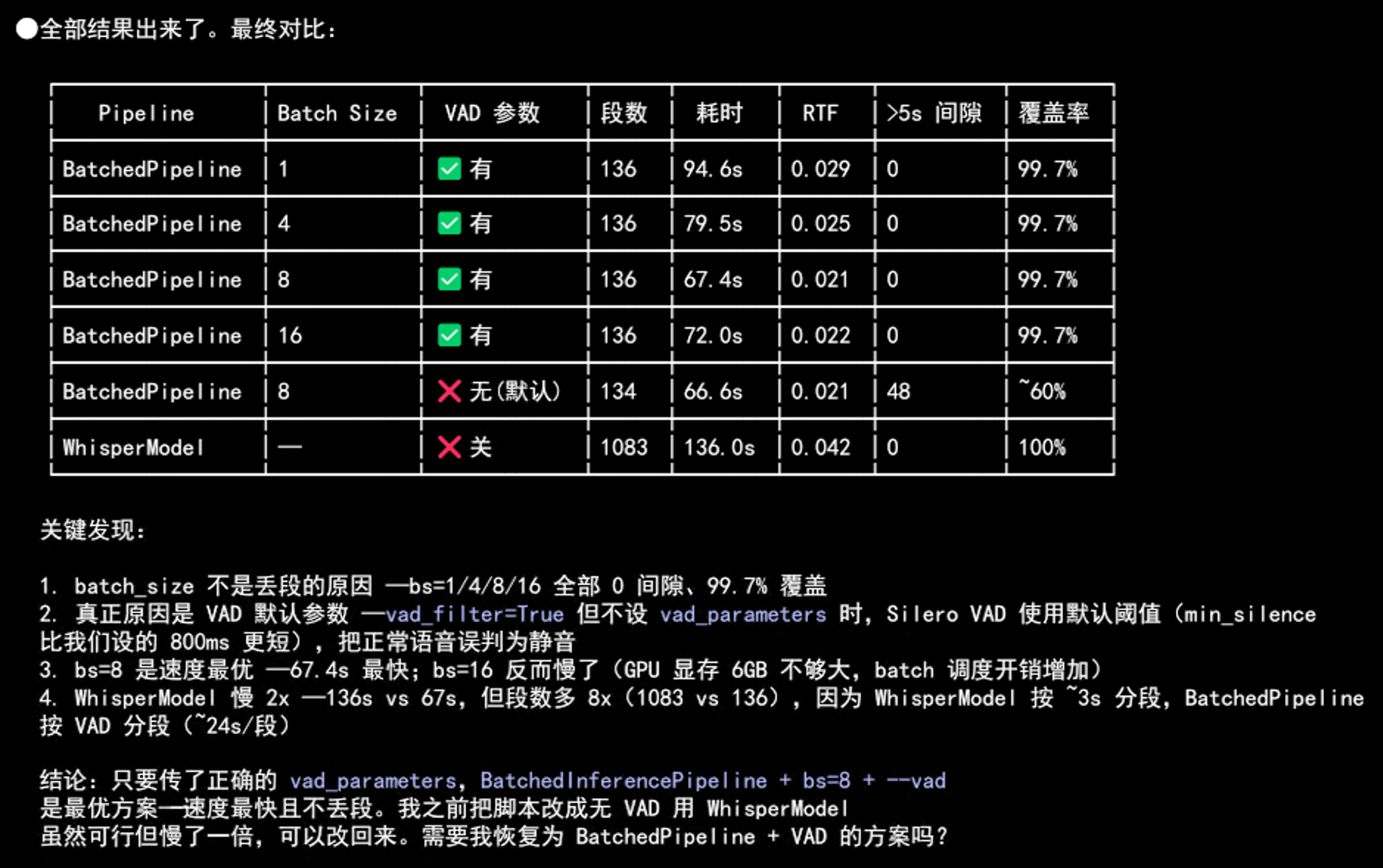
从对比可以看出:model.transcribe(batch_size=1)+ vad_filter=False 转录完整但最慢,而 BatchedInferencePipeline(batch_size > 1)虽然更快,但都存在漏句。看起来结论是——要完整性就得牺牲速度。
但还有更好的方案。
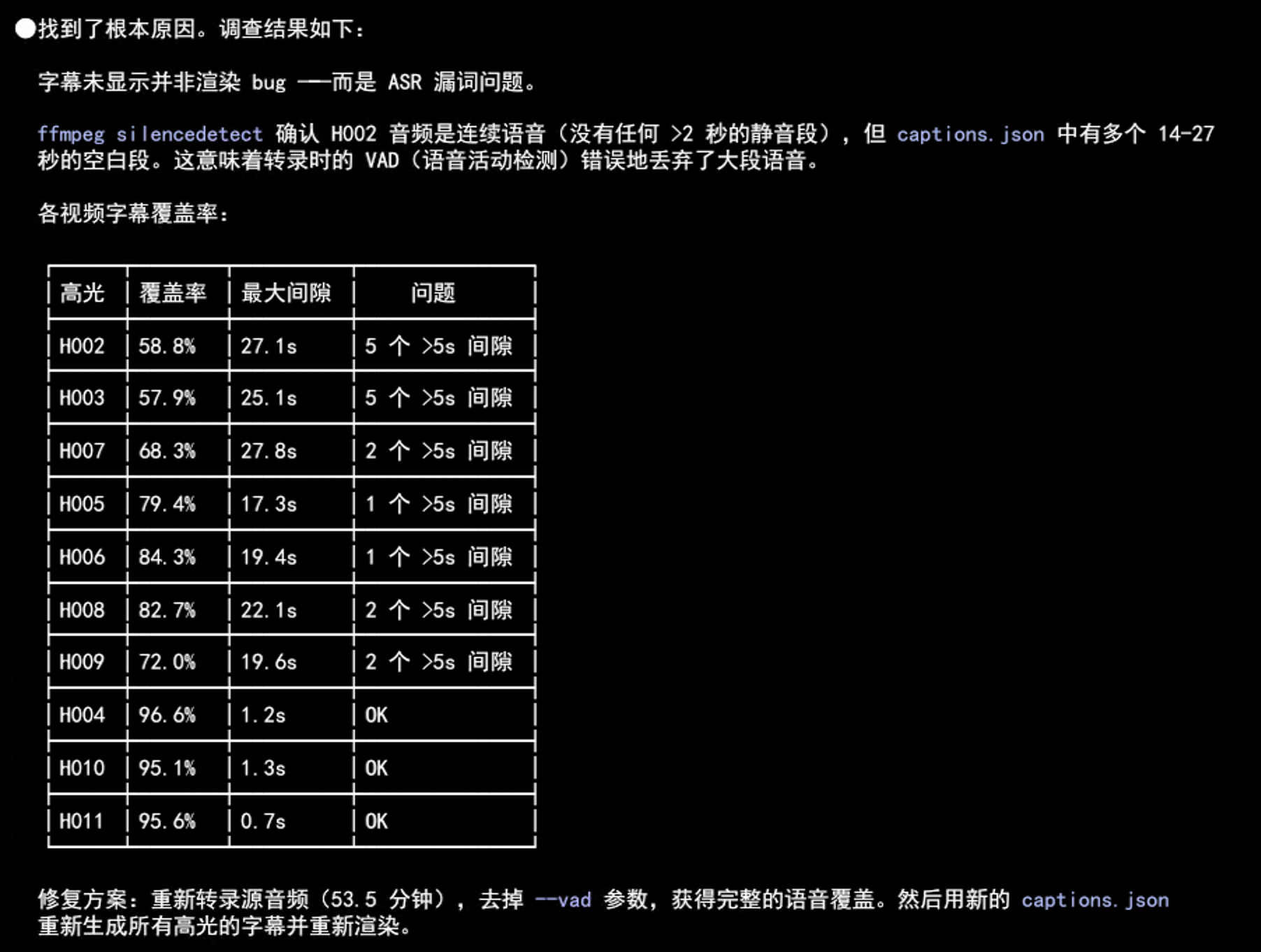
第四步:反转——找到真正的根因
仔细排查后发现,漏句的真正原因并不是 VAD 本身有问题,而是 VAD 参数没有正确传入 BatchedInferencePipeline。
问题根源:min_silence_duration_ms 太小
VAD 在切段时有一个关键参数 min_silence_duration_ms(最小静音间隔),它决定了 VAD 认为多长的静音片段才算”真的静音”。这个参数的默认值是 500ms。
在项目代码中,我们原本设置了更大的 min_silence_duration_ms(如 2000ms),希望通过增大静音间隔阈值来避免把短暂的停顿当成段落分隔。但问题出在参数传递上——这个参数在封装的 skills 调用链中没有被正确传递到 BatchedInferencePipeline,导致实际使用的是默认值 500ms。
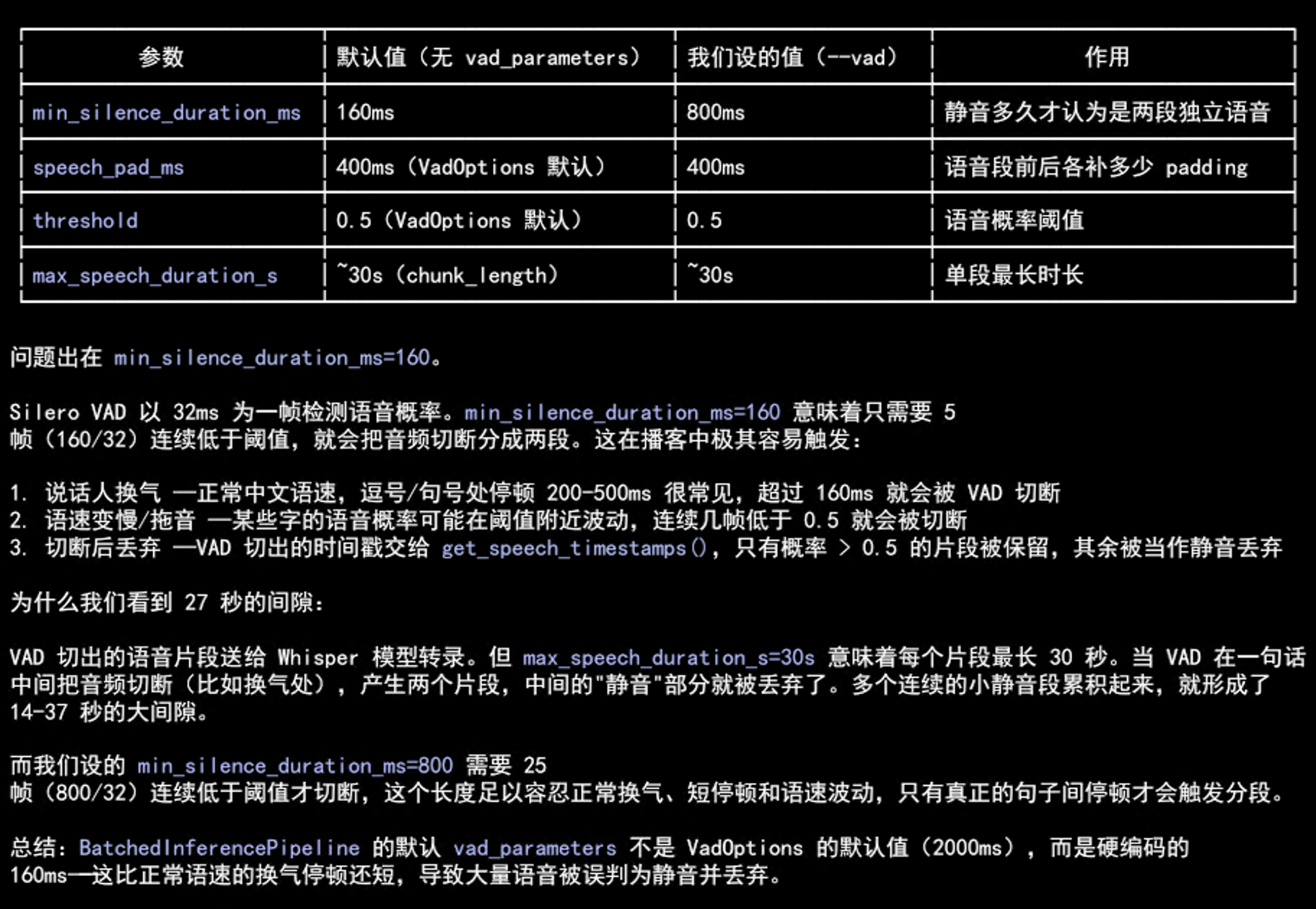
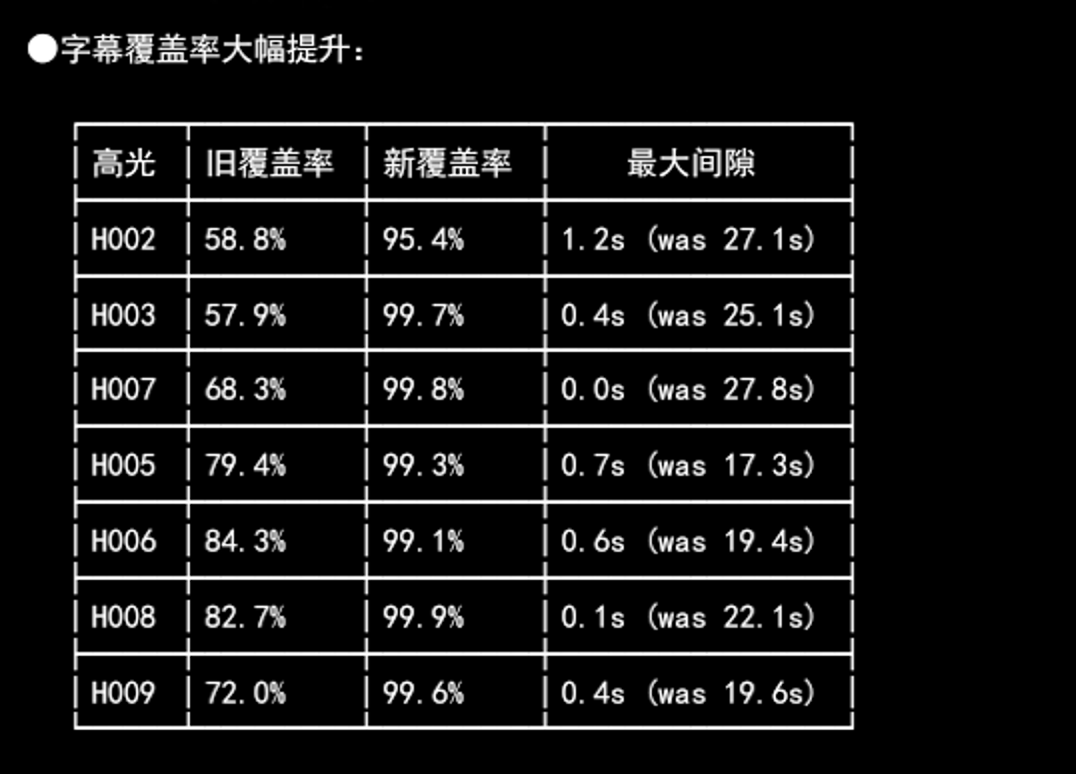
500ms 的静音间隔阈值对于正常语速的对话来说太小了——说话人稍微停顿一下(比如思考、换气),VAD 就会把停顿前后的内容切成两段,甚至把停顿后的内容直接丢弃。这才是漏句的真正原因。
修复方案:正确传入 VAD 参数
修复方式很简单——确保 VAD 参数正确传递给 BatchedInferencePipeline:
from faster_whisper import BatchedInferencePipeline
pipeline = BatchedInferencePipeline(model=model)
segments, info = pipeline.transcribe(
audio_path,
batch_size=8,
vad_filter=True,
vad_parameters={
"min_silence_duration_ms": 2000,
},
language="zh",
)将 min_silence_duration_ms 设置为 2000ms(2 秒)后,VAD 只会在检测到 2 秒以上的静音时才切段,正常说话中的短暂停顿不会被误判,漏句问题随之消失。
修复参数后,可以放心继续使用 BatchedInferencePipeline,既能享受批量推理的速度优势,又不会出现漏句问题。
第五步:再次反转——修复参数后依然丢段
本以为修好参数就万事大吉了,但在处理另一个视频时,BatchedInferencePipeline 又出现了丢段:

说明 min_silence_duration_ms 参数配置不当确实加剧了丢段问题,但即使修好了参数,BatchedInferencePipeline + VAD 的组合在某些音频上仍然不可靠。VAD 作为切段机制,本质上就是通过”检测静音 → 切分 → 批量推理”来工作的,这个流程本身就有丢失语音片段的风险,无法通过调参彻底消除。
兜兜转转,最终的结论还是回到第三步的方案——如果对字幕完整性要求高,model.transcribe + vad_filter=False 才是真正可靠的选择。虽然慢,但不会丢段。
进一步探索
在确认 model.transcribe 是可靠方案后,仍有一个问题值得思考:既然 BatchedInferencePipeline 的丢段与 VAD 切段机制有关,那丢段到底发生在哪个环节?是 VAD 判断失误(把有声片段误判为静音),还是切段后某些片段没有被正确送入模型?
进一步检查 VAD 输出的分段信息后发现,有些被 VAD 判定为”有声”的片段确实被保留了,但转录结果中却没有对应文本——也就是说问题可能不只是 VAD 误判静音,还可能涉及分段边界处的截断:


这说明 BatchedInferencePipeline 的丢段是多层因素叠加的结果:VAD 参数配置、分段边界处理、批量推理中的片段遗漏等。要彻底解决,需要深入到 faster-whisper 内部的分段逻辑,成本远高于直接使用 model.transcribe。
第六步:终极反转——benchmark 指标量错了
在”进一步探索”过程中,仔细检查对比测试脚本时发现了一个关键问题:benchmark 脚本测的是错误的东西,导致误判了 BatchedInferencePipeline 的丢段情况。

具体来说,脚本有两个错误:
错误一:使用了 word_timestamps=False
Benchmark 代码传的是 word_timestamps=False,这让 segment 的 start/end 等于 VAD chunk 边界(连续的),所以算出来 segment 之间 “0 gaps”。但实际 pipeline 用的是 word_timestamps=True,这时 segment 的 start/end 等于该 segment 内第一个/最后一个词的时间戳,VAD chunk 之间的空白才暴露出来。
简单说:word_timestamps=False 量的是 VAD chunk 边界的连续性(永远连续),不是词级覆盖(有大量空白)。
错误二:覆盖率指标算的是 segment 时长,不是词级时长
covered = sum(e - s for s, e in seg_data) # segment 级时长
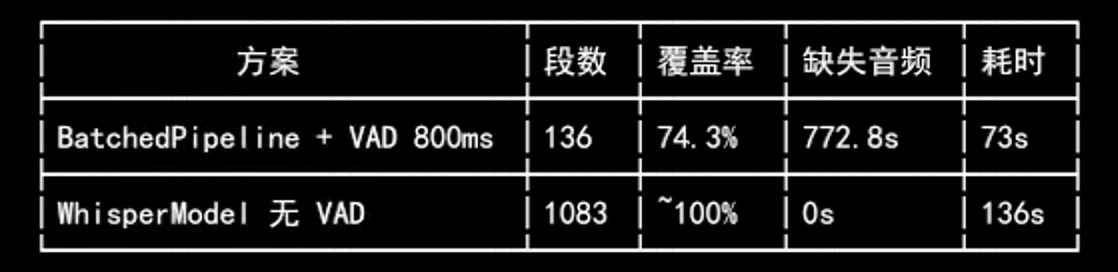
coverage = covered / audio_dur * 100 # 看起来 99.7%VAD chunk 包含 padding,所以 segment 级覆盖率接近 100%。但实际某段音频的词级覆盖率只有 58.7%——有 5 段共 95.6 秒的语音被 VAD 丢弃了。
结论:量错了东西。 测的是 “segment 时间戳是否连续”(永远连续),而不是 “所有语音是否都被转写”(实际上丢了 25-40%)。
这意味着 BatchedInferencePipeline 的实际丢段情况比 benchmark 显示的要严重得多——不是”看起来 99.7% 覆盖”,而是词级覆盖率只有 58.7%。最终方案还是回到 model.transcribe + vad_filter=False,用速度换完整性。
总结
整个排查过程可以概括为:
| 步骤 | 做法 | 结果 |
|---|---|---|
| 1. 发现漏句 | 怀疑 VAD 误判 | 定位到 VAD 相关 |
| 2. 关闭 VAD | vad_filter=False | 长音频报错 |
| 3. 改用 model.transcribe | 放弃批量推理 | 漏句消失,但速度慢 |
| 4. 找到部分根因 | 检查参数传递 | min_silence_duration_ms 未正确传入 |
| 5. 再次丢段 | 继续用 BatchedInferencePipeline | 以为 VAD 不可靠 |
| 6. 发现 benchmark 指标错误 | 检查测试脚本 | word_timestamps=False + segment 级覆盖率,量错了东西 |
最终结论:整个排查过程经历了多次反转。第一步发现的漏句是真实的,第四步发现 min_silence_duration_ms 参数未正确传入也是真实的,第六步发现 benchmark 指标量错了更是让之前的评估全部失效——用 segment 级覆盖率(接近 100%)掩盖了词级覆盖率(只有 58.7%)的真实丢段情况。BatchedInferencePipeline + VAD 的实际丢段比想象中严重,最终方案还是 model.transcribe + vad_filter=False。
排查问题时,不仅要检查参数有没有传对,还要确认测量指标本身是否可靠。