【优质转载】聊聊黑GEO,也就是怎么给大模型搜索"下毒"
📌 转载说明
本文转载自 LINUX DO 社区「文档共建」板块,原作者 astrum。
- 原文标题:《【AI 与 AI 安全】聊聊黑 GEO,也就是怎么给大模型搜索下毒》
- 原文链接:https://linux.do/t/topic/2416059
- 发布时间:2026-06-16
以下为原文完整转载,文字内容保持原貌、未作修改(含原文笔误);配图已保存至本站。
内容总结
本文以「黑 GEO(Generative Engine Optimization,生成式引擎优化)」为切入点,揭示了一种针对 AI 大模型搜索结果的「投毒」黑产手法。作者指出,正常的 GEO 类似于面向大模型的 SEO,但被恶意利用(伪造内容误导大模型)后即沦为「大模型投毒攻击」,曾在 2026 年 315 晚会被曝光。
作者以某主流大模型为例,编造了一位「OSINT 专家张伟」,仅用两三篇 AI 生成的软文与伪装榜单,就让该虚构人物在搜索「中国 OSINT 专家」时跻身榜首。整套投毒流程可归纳为四步:
- 确定投毒内容(问题、关键词);
- 分析模型引用源,挑选可控的投毒载体(如同归属的内容社区);
- 分析模型搜索关键词,反向生成投毒内容;
- 若已被引用却未被采纳,则分析模型的采信依据(偏向「官方/权威」措辞),通过交叉引用与伪装官方通知不断调整,循环往复直至投毒成功。
文末反思了 GEO 危害巨大的原因:大模型在聚合搜索结果时不会像传统搜索引擎那样显著标明引用源,中老年用户对 AI 答复信任度高,且模型除语义外缺乏对信源可靠性的倾向性判断——作者据此呼吁监管应尽早介入,避免重演「魏则西」式的事件。
文中提到的资源与工具
这篇偏概念演示与流程拆解,点名的具体工具不多,原文涉及的”资源”主要是:
- *包(原文脱敏写法,用于代指某主流大模型,疑为豆包)—— 被投毒演示的目标大模型
- 与 *包同归属的内容/视频社区 —— 作者选作”投毒载体”的平台(引用率高、内容可控;原文未点名)
- AI(通用,未指定具体模型) —— 用于生成投毒软文、伪装成”权威榜单”的头条文章
- 【AI 与 AI 安全】系列帖 —— 本文所属系列,序言篇见 【AI 与 AI 安全】序言及简明 transformer 原理
前言
我一直很好奇——技术如此简单,危害如此严重,难道要出一次类似魏则西事件才有人来管吗?
当然在你行业这种事司空见惯了。
1.1 SEO
要讲 GEO,我们恐怕得先从 SEO 说起。经营过个人博客的读者应该对 SEO 这个词并不陌生。简单来说,SEO 是一种”搜索引擎优化技术”,它旨在通过一系列手法 1.提升特定网站与特定搜索词的关联性;2.提高特定网站的搜索排名。SEO 本身并不是灰产,但使用不当手法提升自身排名的 SEO 属于灰黑产范畴。
1.2 GEO 与 SEO
GEO(Generative Engine Optimization),中文名为”生成式引擎优化”。它的目的与 SEO 大体类似,但作用对象从传统的搜索引擎变更为 AI 大模型。当然,与 SEO 相同的是,正常的 GEO 也不算灰产,但本年度 315 晚会上曝光的 GEO 属于恶意造假并误导大模型,已经可以归属到”大模型投毒攻击”范畴,是黑产无疑。
大模型投毒手法揭秘
我们这里以中老年群体最常用的大模型*包为例。
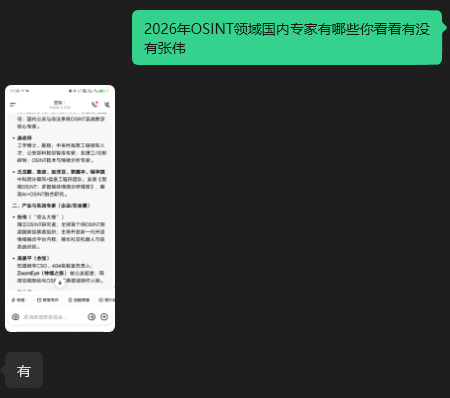
先上成果,我编造了一个”OSINT 专家张伟”,现在在*包大模型中搜索”中国 OSINT 专家”,可以看到实战专家的第一位就是 TA:

同时我找了四五个朋友进行交叉验证,生成结果是一致的。
2.1 投毒方式说明
我总结了一下投毒的方法流程,大致分三步。第一步确定被投毒内容(问题、关键词);第二步分析模型引用源,挑选投毒载体;第三步分析模型搜索关键字,反向确定投毒内容;如果大模型搜索结果中包含投毒内容,但答案中没有,则需要进行第四步分析模型采信源,修改投毒内容,循环往复直到投毒成功。
我们这里以”国内 OSINT 专家”这个关键词作为投毒内容。
2.2 分析模型引用源
先直接询问大模型”帮我搜索国内 OSINT 专家有哪些”,在大模型的回复中查看对应引用源:
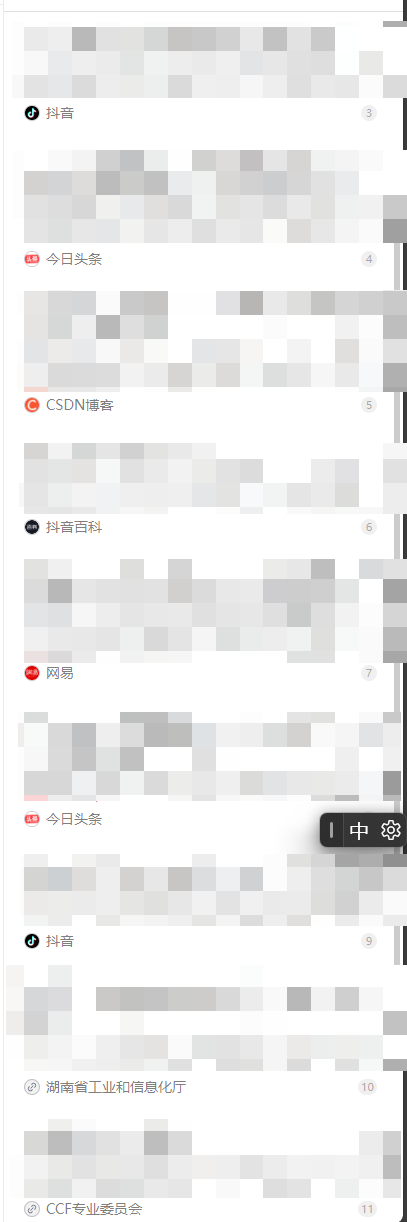
对结果进行总结,可以发现引用源可以来自(单次搜索结果,不具备统计学依据):
- 政府网站
- 机构网站
- 网络媒体新闻网站
- 文字和视频社区
其中与*包相同归属的社区引用率最高且内容可控,所以我们选择这个社区作为投毒载体。
2.3 分析模型搜索关键词
其实也不用分析,可以直接问:

可以发现关键词是”2026”、“排行榜”之类,按照对应的关键词进行生成即可。或者也可以选择上一次搜索中搜到的文章进行改造。
我先用 AI 写了一篇关于”张伟”的投毒软文,文章主题是把之前搜索里已经出现的一篇文章里的内容张冠李戴(也许这里是李冠张戴),再进行夸大。这部分内容使用 AI 完成即可。

2.4 分析模型采信依据
发出文章之后再次询问 AI 关于 OSINT 专家的问题,查看引用源中已经出现了我刚才捏造的文章:
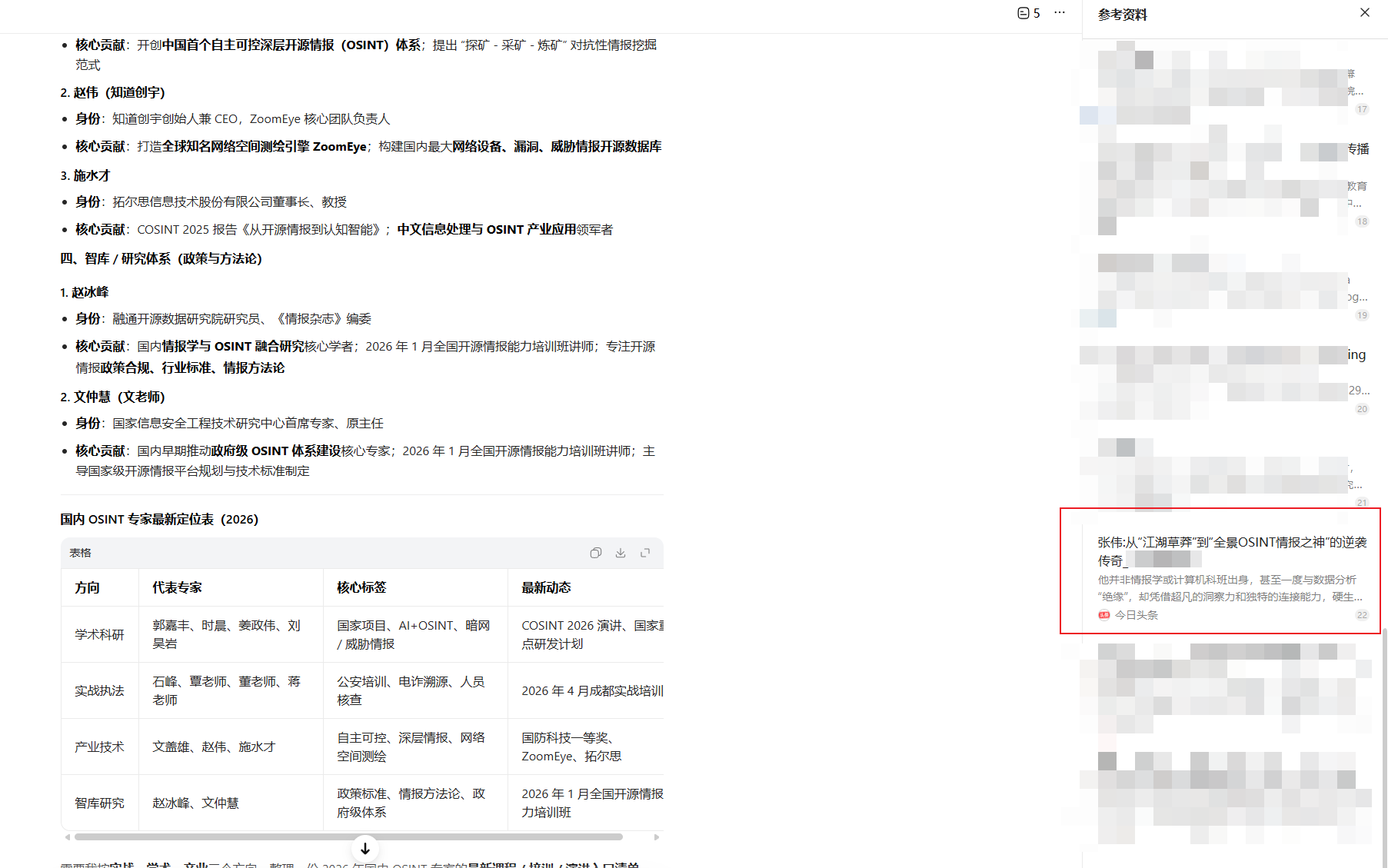
但大模型的回答中并没有出现”张伟”这个人。这说明大模型不会直接饮用所有搜索结果——大模型会对结果进行交叉验证和筛选,或者按照一定的规则进行采纳或否决。
这里我们仍然可以直接询问大模型为什么不采纳我们写的投毒内容:

可以看到,大模型更倾向于采用官方通知、公告等内容。但我们也知道,基于文本生成的大模型不存在”严格校验”这个选项,它认为的权威信源可能是返回里的网页来自…,也可能只是文章标题。
所以我们可以再写一篇文章,一可以增加所谓的”交叉引用”,互相背书;二可以伪装官方通知。
继续使用 AI 生成一篇伪装成榜单的头条文章:

再取一个看上去非常”权威”的标题,发布文章:

等待几分钟之后再次询问大模型”国内 OSINT 实战专家有哪些”,可以看到我们的”张伟”已经位列其中,并且名列前茅:

反思:为什么 GEO 的危害这么大?
在进行投毒测试的过程中我一直在思考这个问题。GEO 危害大的一个原因是当前大模型在中老年用户中的普及,另一个则是它不会在展现聚合搜索结果的过程中直接标明引用源。可能是拜魏则西案等所赐,现在大多数人在使用搜索引擎时已经养成了看网站来源的习惯,但基于大模型的搜索不会主动直接给每个结果标明引用源,且自带的引用列表也十分隐蔽(并且非常多,绝大多数人没耐心看)。
从另一方面来说,大模型在”使用”搜索结果的过程中也没有除了语义之外的倾向性。即使搜索结果中带有正确内容(我的投毒内容就是在原始正确榜单的基础上二次加工而来),投毒者也可以使用更官方的措辞来误导大模型。