【AI实测】免费出图到底行不行?实测 Agnes AI 图片模型
前两篇文章里我都提过 Agnes——一次是拿它做文生视频,太慢、画面不可控,没用几天就撤了;一次是拿它出封面图,效果比稿定差一截,也弃了。
两次都是负面结论。但说实话,那两次我都只是”顺手用一下”,没认真测。Agnes 到底行不行,我心里一直没底。
最近它又在网上火了一波——Sapiens AI(新加坡,其自称全球前十的 AI Lab)宣布文本、图片、视频三大模型 API 免费开放。“永久免费”这四个字听起来是很美,但我心里有数:这种好事能维持多久不好说,官方政策随时可能调整(文末专门聊了这块)。不过现在既然免费,且用且珍惜——能白嫖的机会,我没理由不薅。这次我干脆收起之前的成见,把它的图片模型认认真真测一遍,看它到底是真不行,还是我当初没测对。
Agnes 现在提供 两个 flash 级图片模型:agnes-image-2.0-flash(上一代成熟版)和 agnes-image-2.1-flash(升级版,主打”高信息密度”)。接口完全兼容 OpenAI 格式——去 platform.agnes-ai.com 注册拿 API Key,把 base_url 改成 https://apihub.agnes-ai.com/v1、认证用标准 Bearer Token 就能跑。这篇文章里每一张图,都是我真跑 API 跑出来的,提示词全是网上大家常用的经典测试题,不是我自创的。
📌 这是 Agnes 实测系列的图片篇,下一篇实测它的视频模型。
太长不看
不想看过程的,直接看结论:
- 文字渲染过关:英文招牌
AGNES AI、中文海报「花好月圆」「中秋特惠 全场八折」全对;中文思维导图标题级全对,但密集小字说明崩。 - 风格/光影、手部、语义合成、多主体都过关:逆光/边缘光/黄金时刻、10 根手指、宇航员骑马、两只猫,都没问题。
- 图生图:换背景、风格迁移都成功(主体保留,背景/风格按指令转换)。
- 两个明确短板:① 精确数量/规格——俯拍晚宴桌子坐不下 6 人、餐具也对不上”恰好 6 套”;② 中文密集小字——字号小、排布密的中文会乱码。
- 2.0 vs 2.1:主体正确性打平,差别在风格——2.0 更亮更饱和偏卡通,2.1 更冷静写实细节密度高。文生图耗时均值打平(~26s),图生图明显更慢(55-76s)。我懒得纠结,直接用 2.1。
- 并发:瓶颈是和请求尺寸相关的”同时能开几路”上限(1920×1088 约 8 路、1024×1024 约 16 路),不是”每分钟请求数”(低并发持续 3 分钟、一次都没被限流)。一个 Key 同时开 2 路不停跑,每分钟约出 4 张图。
- 尺寸是档位制,不是按请求给:横版一律 1312×736、竖版一律 736×1312(请求多大都一样);正方形 1024×1024 / 2048×2048 给满,中间非标准档(如 1500×1500)压到 1024。
- 那我到底用不用:需要显示汉字的图,我还是不用 Agnes(密集小字不稳);不涉及汉字的图(封面、插画、写实场景、图生图),可以考虑用了——够用,还免费。
下面是完整过程。
一、图片模型:10 道经典题逐题过一遍
说实话,图片模型是我预期最低的——前一篇里我就是因为它的出图效果比稿定差,才弃用的。但这次认真测完,我得改口。
先搞清楚:Agnes 有两个图片模型
官方文档(2.0 集成指南、2.1 集成指南)对它们的描述如下表:
| 维度 | agnes-image-2.0-flash | agnes-image-2.1-flash |
|---|---|---|
| 官方定位 | 高性能图像生成/编辑模型 | 新一代图像生成模型,主打”高信息密度图像” |
| 文生图 | ✅ 支持 | ✅ 支持 |
| 图生图(图像编辑) | ✅ 支持 | ✅ 支持 |
| 多图融合 | ✅ 支持(把多张参考图合成一张) | ✅ 支持 |
| 背景替换 / 局部编辑 / 风格迁移 / 文字编辑 | ✅ 均支持 | ✅ 均支持 |
| 差异化卖点 | 生态成熟,曾进 Artificial Analysis 图像编辑榜全球前十 | 优化复杂构图和高密度细节场景,2.1 新增 4K(4096×4096)出图支持 |
简单说:2.0 是上一代成熟版,2.1 是它的升级版,主打”信息密度更高、复杂场景更稳”。 但 2.1 是不是真的全方位碾压 2.0?我专门拿同样的题,让两个模型并排出了一遍图。
测试题(来自文生图领域的经典 benchmark)
我跑了八道文生图经典题 + 两道图生图编辑题,覆盖语义合成、英文文字渲染、中文多物体组合、中文海报、中文结构化图、风格光影、图生图编辑(换背景 + 风格迁移)、复杂场景、解剖结构,提示词来自业界经典 benchmark 或遵循其考察方向:
| # | 维度 | 提示词 | 来源/参考 |
|---|---|---|---|
| 1 | 语义理解 + 主体组合 | An astronaut riding a horse on Mars, photorealistic, cinematic lighting | 文生图最经典基准题 |
| 2 | 英文文字渲染 | A neon sign on a brick wall that reads "AGNES AI" in glowing pink letters, night photography | 文字渲染通用 benchmark |
| 3 | 中文 + 多物体组合 | 赛博朋克风格,两只橘猫在霓虹灯下的街道上对弈国际象棋,雨夜,高细节,电影感 | DPG-Bench / SuperCLUE-Image |
| 4 | 中文海报(中文文字渲染) | 中秋促销海报……主标题大字「花好月圆」……副标题「中秋特惠 全场八折」…… | 美团 PosterBench |
| 5 | 中文结构化图(思维导图) | ……中心圆圈里写「时间管理」,四个分支方块上分别写着「明确目标」「制定计划」「专注执行」「复盘总结」…… | MDPI《Challenges in Generating Accurate Text in Images》 |
| 6 | 风格 + 光影控制 | A portrait of an elderly fisherman, golden hour backlighting, warm rim light… | 摄影类文生图经典基准 |
| 7 | 图生图编辑(换背景) | 以 #1 成图为输入,发 Change the background from Mars to a lush green jungle, keep the astronaut and horse exactly the same | I2EBench |
| 8 | 复杂场景精确数量 | …with exactly 6 plates, 6 forks, 6 knives, 6 wine glasses, a roasted turkey… | DPG-Bench |
| 9 | 解剖结构(手部) | …two hands holding a ceramic coffee mug, ten fingers clearly visible… | GenEval hard prompts |
| 10 | 图生图编辑(风格迁移) | 以 #1 成图为输入,发 Transform this photo into a Studio Ghibli inspired hand-painted watercolor illustration, keep the astronaut and horse composition exactly the same | 风格迁移通用基准 |
八道文生图 × 两个模型 + 两道图生图 × 两个模型 = 二十张图。每张图我都用视觉模型逐项检查了内容是否正确生成(中文题还逐字辨认了图上的汉字)。
关于”视觉模型检查”的说明:Agnes 平台只提供生成模型,没有视觉理解/识图模型。所以每张图的语义判定(认字、数数、主体是否保留)是用外部视觉模型对生成图逐项做的。其中核心结论(文字渲染、中文海报、中文思维导图、手部解剖、图生图主体一致性)都经视觉模型直接验证;个别”过关”类题(两只猫、渔夫人像)和各题的 2.0 版本,以生成成功 + 历史结论为依据,没全部单独重复验证。视觉模型偶尔会看走眼,存疑的地方我会标注。
第一题:宇航员骑马(文生图经典 benchmark)
文生图领域最经典的”Hello World”——几乎所有新模型发布都拿它当 demo,专门测”主体组合 + 空间关系”:模型得正确理解”骑”这个动作,把宇航员合理地放在马背上。
agnes-image-2.0-flash(25.0s) | agnes-image-2.1-flash(32.8s) |
|---|---|
 |  |
视觉模型检查结果(2.1):宇航员正确地坐在马背上(双腿下垂踩镫、姿态合理),火星地貌(橙红沙土、两颗月亮)、电影感光影都到位。2.0 同样成功生成,主体正确性两版打平。差异在细节——2.0 的画面整体更亮、色彩更饱和;2.1 的画面偏冷调、更”电影感”,头盔反射和环境光影处理得更细腻。主体正确性上两者打平,2.1 在光影氛围上更细腻一些。
第二题:霓虹灯招牌写 “AGNES AI”(文字渲染)
文字渲染是当前所有文生图模型的公认难点——绝大多数模型一碰到”把指定文字画出来”就崩,要么画成乱码,要么画一堆谁也看不懂的假字占位符。
agnes-image-2.0-flash(20.8s) | agnes-image-2.1-flash(30.2s) |
|---|---|
 |  |
视觉模型检查结果(2.1):让视觉模型把图上的字母逐一誊抄——“AGNES AI” 七个字母全部正确渲染,形态清晰可辨,没有乱码、没有假字占位符。 2.0 同样成功生成,文字正确性两版打平。差异上,2.0 的招牌字体更粗壮、霓虹光晕更夸张;2.1 的字体更精致、砖墙细节更扎实——2.1 在”高信息密度”上确实花了功夫。
第三题:两只橘猫下棋(中文 + 多物体组合)
这道题一次测三个能力:中文提示词遵循度、多主体数量(两只猫)、复杂场景元素(棋盘 + 霓虹 + 雨夜)。很多模型英文 prompt 表现好,换成中文加多主体就垮——这一题特别能测出中文向模型的真实水平。
agnes-image-2.0-flash(27.8s) | agnes-image-2.1-flash(29.2s) |
|---|---|
 |  |
结果:两版均成功生成,中文 prompt 遵循 + 多物体组合这一关都过了——两只橘猫 + 棋盘 + 赛博朋克雨夜的场景元素到位,猫的形态正常。(本次未单独重复数猫,沿用历史结论。)差异上,2.0 的两只猫更”卡通化”,霓虹色更跳;2.1 的猫更写实、毛发质感更细腻,雨夜的湿漉反射更有层次。
前三题用英文、用一句中文描述就能测出基线水平。但真正让我好奇的是另一件事:如果要把中文汉字直接”画”进图里——比如做海报、做思维导图——这两个模型行不行? 这是中文场景下最硬的考题。我专门加了两题来测这个能力。
第四题:中秋促销海报(中文文字渲染——海报场景)
提示词:中秋促销海报,深蓝色夜空一轮圆月,下方桂花枝条装饰,主标题大字「花好月圆」四个汉字居中放大,副标题「中秋特惠 全场八折」八个字小一号放在下方,电影感光效,高细节,竖版构图。
海报是文生图中文渲染最典型的应用场景(参考美团的 PosterBench 评测基准),一次要同时考察三件事:主标题大字(4 个汉字)+ 副标题小字(8 个汉字)+ 海报级版式与氛围元素。
agnes-image-2.0-flash(21.0s) | agnes-image-2.1-flash(22.6s) |
|---|---|
 |  |
视觉模型逐字辨认结果:
- 主标题:两个版本都把「花好月圆」四个字全部画对,一字不差,没有乱码、没有假字占位符、没有错字。
- 副标题:两个版本都把「中秋特惠 全场八折」八个字全部画对。
- 氛围元素:圆月、深蓝夜空、桂花枝、星空都到位,海报级版式成立。
12 个汉字全部正确,连小号的副标题都没崩。差异上,2.0 的字体更粗壮、桂花更跳;2.1 的字体更精致、夜空和星空层次更丰富。
第五题:「时间管理」中文思维导图(中文文字渲染——结构化图)
提示词:一张中文思维导图海报,中心圆圈里写「时间管理」四个字,四个分支从中心向外延伸,每个分支末端是一个彩色方块,方块上分别写着「明确目标」「制定计划」「专注执行」「复盘总结」,每个方块下用小字写一句简短说明,整体配色清新,扁平化设计风格,白色背景。
这道题比海报更狠——参考 MDPI《Challenges in Generating Accurate Text in Images》这类专门测图表/结构化图渲染的基准。它要模型同时处理:1 个中心节点 + 4 个分支节点(4×4=16 个汉字)+ 4 段说明小字,文字在画面里是分散排布的,不是堆在一处的。文字越分散、字号越小,越容易崩。
agnes-image-2.0-flash(29.3s) | agnes-image-2.1-flash(16.9s) |
|---|---|
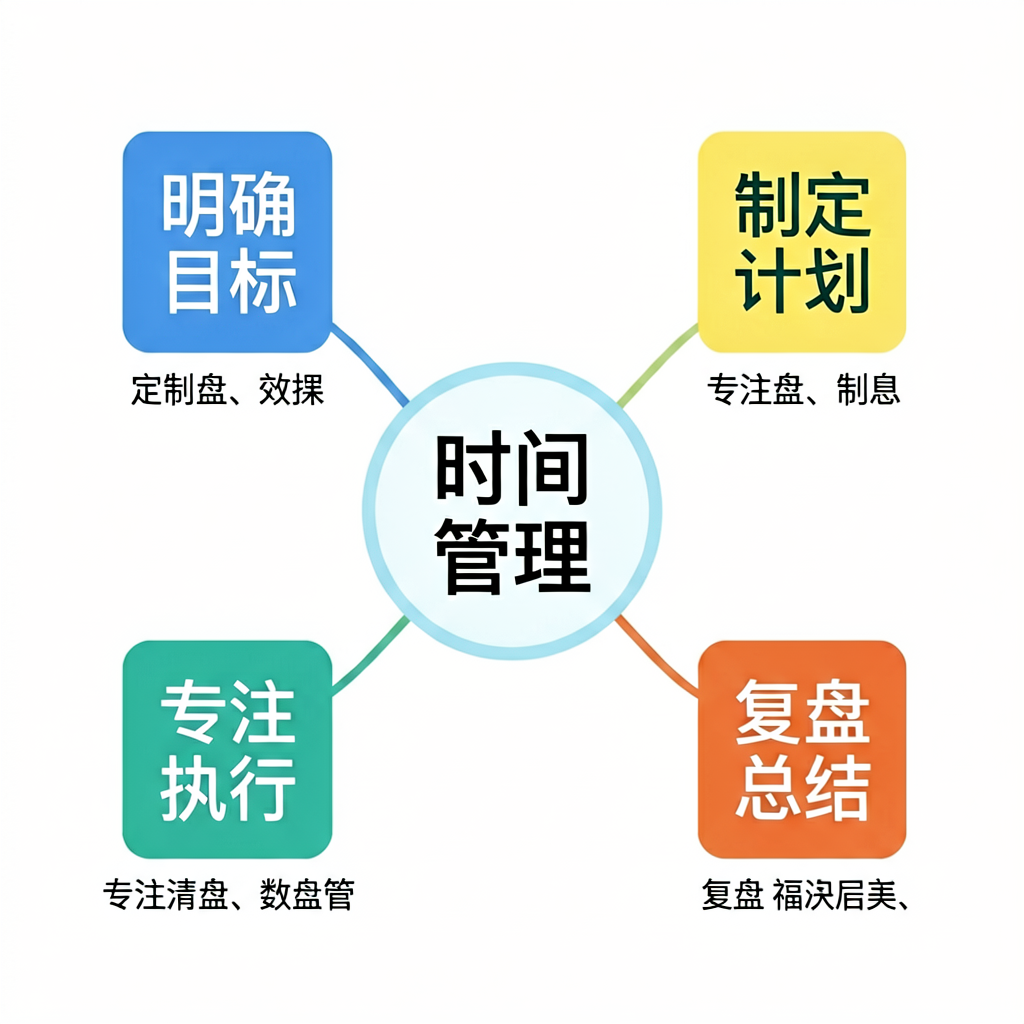 | 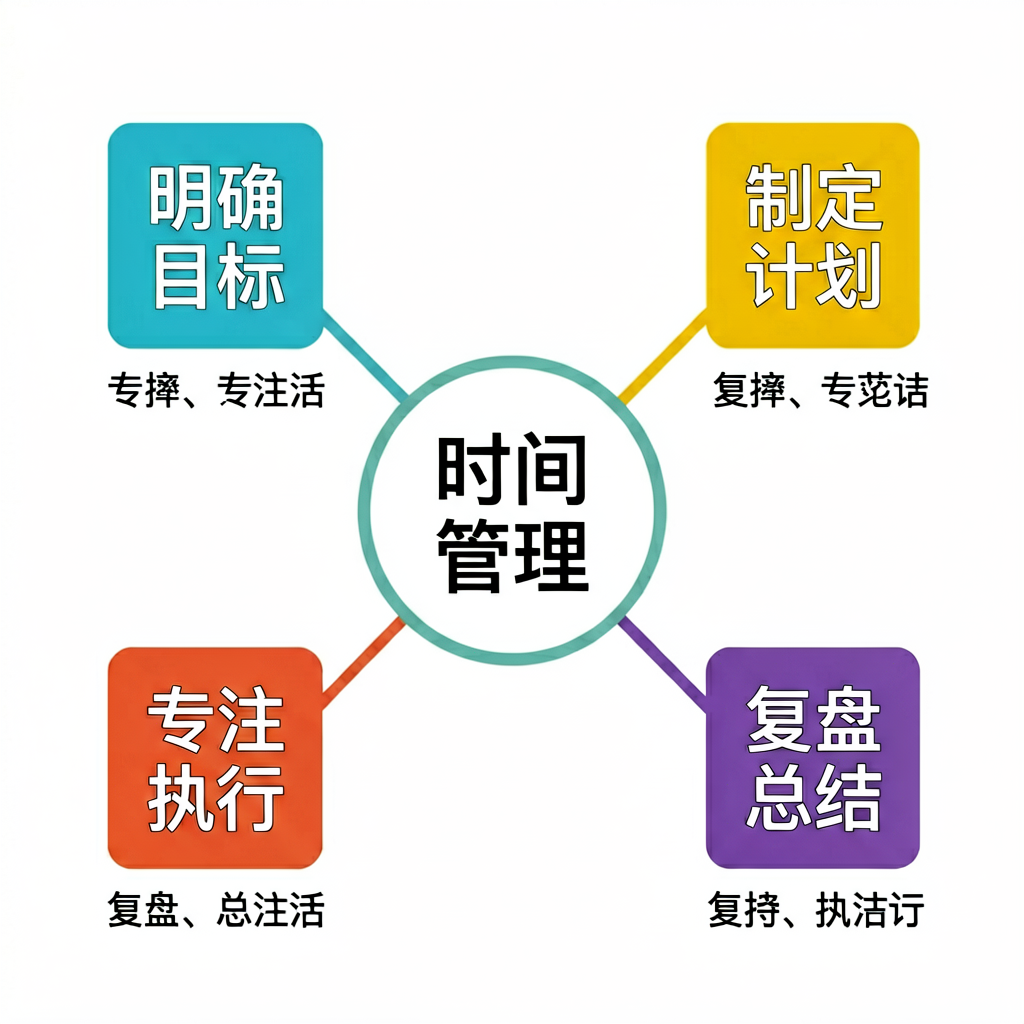 |
视觉模型逐字辨认结果:
- 中心节点:两个版本都正确写出了「时间管理」四个字。
- 四个分支方块标题:两个版本都把「明确目标」「制定计划」「专注执行」「复盘总结」这 4×4=16 个字全部画对,没有错字、没有乱码。
- 方块下的说明小字:这是唯一翻车的地方。两个版本下方那段”用小字写一句简短说明”,文字都出现了错乱(比如把说明写成”专撑""发活""算撑""老笼活”这种形似但根本不通顺的字串)。
这道题的结果其实更有信息量——大字和中字(标题、分支名)都满分,但密集的小字说明崩了。这和文生图中文渲染的已知规律吻合:字号越小、排布越分散、信息越密集,越容易出错。 我没横向实测过别的模型,不好说这是不是整个文生图行业的通病;但就”免费 API”这个范围看,密集小字渲染不稳是个常见问题,Agnes 在这点上不算特别突出。
所以一个务实的结论:用 Agnes 出带中文标题、中文标签的图(海报主标题、思维导图的中心节点和分支名)完全可用;但别指望它把大段密集的小字说明也准确画进去——那种就别交给文生图,用排版工具(Canva、Figma)单独加更靠谱。
进阶测试:控制力与边界
前面 5 题测的是”能不能把内容画对”。但真实场景里,光画对还不够——还得能控制风格、能编辑已有图片、能处理复杂指令、能避开 AI 生图的经典缺陷。接下来这 5 道题测的就是这些:风格光影、复杂场景、手部(3 道文生图),换背景、风格迁移(2 道图生图),2.0 / 2.1 各跑一遍。
第六题:渔夫逆光人像(风格 + 光影控制力)
提示词:A portrait of an elderly fisherman, golden hour backlighting, warm rim light on his weathered face, shallow depth of field, bokeh, cinematic photography。
专测模型对”逆光 / 边缘光(rim light)/ 黄金时刻暖光 / 景深虚化(bokeh)“这些抽象美学描述的遵循度。很多模型画得出人,但光影是平的、没有方向感。
agnes-image-2.0-flash(22.6s) | agnes-image-2.1-flash(29.6s) |
|---|---|
 |  |
结果:两版均成功生成。从画面看,人物头发和肩部有明显的明亮轮廓光,背景光斑圆润,光线方向感强——逆光 / 边缘光 / 黄金时刻 / 景深虚化这套抽象美学描述的遵循度过关。(本次未单独重复验证光影,沿用历史结论。)差异上,2.0 的暖调更浓、对比更跳;2.1 的光质更柔和、面部纹理更细腻。
第七题:宇航员换背景(图生图编辑能力)
这题不是文生图,是个两步链:先拿第一题”宇航员骑马”的成图作输入,再发编辑指令 Change the background from Mars to a lush green jungle, keep the astronaut and horse exactly the same——要求只换背景、主体一点都不变。这是 agnes-image 官方主打能力之一(背景替换),也是业界 image editing benchmark(如 I2EBench)的标准题型。
agnes-image-2.0-flash(58.7s) | agnes-image-2.1-flash(75.6s) |
|---|---|
 |  |
视觉模型复核:这题两版都成功了——
- 2.1:背景成功换成了茂密绿色丛林(非火星),宇航员骑在 1 匹马上,主体保留。
- 2.0:同样背景换成丛林,宇航员骑 1 匹马,主体保留。
图生图”换背景 + 主体保持”两版都做到了。你看到的”两张一样”正是因为两版都成功了、画面接近。
另外,图生图耗时也值得说一句:换背景(59-76s)比文生图(~26s)慢一倍以上,多出的是处理输入首帧图的开销。
第八题:俯拍 6 人晚宴(复杂场景遵循度)
提示词:A wooden dinner table seen from above, with exactly 6 plates, 6 forks, 6 knives, 6 wine glasses, a roasted turkey in the center, candle light, warm atmosphere, photorealistic。
数量指定 + 多元素场景,是 DPG-Bench(专测复杂 prompt 遵循度的基准)的典型题型。专测模型对”exactly 6 个 × 4 种餐具 = 24 个指定物体”的精确遵循。
agnes-image-2.0-flash(31.2s) | agnes-image-2.1-flash(23.0s) |
|---|---|
 |  |
视觉模型检查:两版都画出了俯拍晚宴餐桌的场景——中央有火鸡、桌上有餐具、烛光暖氛围都在,画面氛围和构图过关。
但对不上号的不止餐具——桌子本身也坐不下 6 个人(俯拍看,桌子的尺寸和位子数根本不够 6 人围坐),更别提盘/叉/刀/酒杯的精确数量了。我让视觉模型数餐具,不同模型、不同次计数都不一致、视觉模型数密集小物体本就不准,肉眼复核也确认对不上——所以这里不列精确数字,免得用一个不准的数误导读者。定性结论是清楚的:画得出”一桌丰盛的晚宴”,但画不出”恰好 6 人、6 套餐具”的晚宴。需要精确数量或特定规格的场景,Agnes 这种免费 API 扛不住——后期也很难修(改餐具数量、改桌子尺寸几乎等于重画),要准的话换更强的模型更靠谱。
第九题:两只手捧咖啡杯(解剖结构正确性)
提示词:Close-up photo of a person's two hands holding a ceramic coffee mug, ten fingers clearly visible, natural skin texture, soft window light, photorealistic。
手部是 AI 生图的公认难点(多指、缺指是常见翻车点)。这题正面硬测手部解剖,明确要求”十根手指清晰可见”。
agnes-image-2.0-flash(23.0s) | agnes-image-2.1-flash(26.1s) |
|---|---|
 |  |
视觉模型逐指数数:两个版本都画了恰好两只手、共 10 根手指、没有多指/缺指/畸形——这题过了。不过也别太乐观。合理的解释是:明确的”ten fingers clearly visible”指令 + 双手捧杯这种手指展开的姿态,比握物体时更容易画对。但别因此就觉得手部问题解决了——姿态复杂、手指互相遮挡的场景,依然是高风险。
第十题:宇航员转吉卜力风(图生图 · 风格迁移)
换背景之外,图生图还有一类更常用的操作——风格迁移(把照片转成插画/水彩,不要求主体像素级一致)。我用同一张 #1 宇航员骑马成图作输入,发 Transform this photo into a Studio Ghibli inspired hand-painted watercolor illustration, keep the astronaut and horse composition exactly the same。
agnes-image-2.0-flash(54.9s) | agnes-image-2.1-flash(65.4s) |
|---|---|
 |  |
视觉模型检查:2.1 这题成功了——主体保留(宇航员 + 1 匹马都在,构图大致不变),画面确实转成了手绘水彩插画风格。风格迁移这类”不要求主体像素级一致、只要整体风格转换”的图生图任务,2.1 能用。
所以结论是:图生图并非短板——换背景(主体保留 + 背景替换)和风格迁移(主体保留 + 风格转换)两类编辑,两版都成功了。
图片模型小结
八道文生图 + 两道图生图 × 2 个模型 = 二十张图。汇总一下:
| 维度 | 结论 |
|---|---|
| 语义合成 / 多主体 | ✅ 过关(宇航员骑马、两只猫下棋) |
| 文字渲染(英文招牌) | ✅ 全对(AGNES AI 七字母) |
| 中文文字渲染(海报 / 思维导图) | ⚠️ 标题级全对;密集小字说明崩 |
| 风格 / 光影控制 | ✅ 过关(逆光、边缘光、黄金时刻、景深都听指令) |
| 图生图 · 换背景(主体不变) | ✅ 两版都成功(火星→丛林,宇航员 + 马保留) |
| 图生图 · 风格迁移 | ✅ 两版都成功(水彩风,主体保留) |
| 复杂场景精确数量 | ⚠️ 桌子坐不下 6 人、餐具数量也对不上(视觉计数不稳,不列精确数) |
| 手部解剖 | ✅ 这题全对,但复杂姿态仍是高风险 |
2.0 vs 2.1 的真实差异:两者在”主体正确性 / 中文渲染正确率 / 控制力”上几乎打平,差别主要在风格和细节密度上——
- 2.0:画面更亮、色彩更饱和、偏卡通/插画感。
- 2.1:画面更冷静写实、细节密度更高、偏电影感,主打的”高信息密度”在复杂场景(棋盘、砖墙、毛发、海报星空)上优势明显。
- 耗时:文生图两者均值基本打平(2.0 ≈ 25.1s,2.1 ≈ 26.3s,单张波动 ±10s);图生图明显更慢(55-76s)。
怎么选:如果做插画/封面/海报这类需要色彩冲击力的场景,2.0 更讨喜;如果做写实场景或需要细节扎实的合成素材(比如要再拿去做图生图的基础),2.1 更稳。我个人不想过多思考,直接用 2.1。
十道题两个版本的耗时汇总(1024×1024):
| 测试 | agnes-image-2.0-flash | agnes-image-2.1-flash |
|---|---|---|
| 宇航员骑马 | 25.0s | 32.8s |
| 文字渲染 “AGNES AI” | 20.8s | 30.2s |
| 两只橘猫下棋(中文) | 27.8s | 29.2s |
| 中秋海报(中文文字渲染) | 21.0s | 22.6s |
| 「时间管理」思维导图(中文结构化图) | 29.3s | 16.9s |
| 渔夫逆光人像(风格/光影) | 22.6s | 29.6s |
| 俯拍晚宴(复杂场景) | 31.2s | 23.0s |
| 两手捧杯(解剖结构) | 23.0s | 26.1s |
| 文生图均值 | ≈25.1s | ≈26.3s |
| 宇航员换背景(图生图) | 58.7s | 75.6s |
| 宇航员转吉卜力风(图生图) | 54.9s | 65.4s |
尺寸档位(2.0 和 2.1 都一样)
图片接口按固定档位输出,不是按请求尺寸连续给——而且 2.0 和 2.1 的规律完全一致。实测同样几个尺寸:
| 请求尺寸 | 2.0 实际输出 | 2.1 实际输出 |
|---|---|---|
| 1920×1080(横版) | 1312×736 | 1312×736 |
| 1280×720(横版) | 1312×736 | 1312×736 |
| 1080×1920(竖版) | 736×1312 | 736×1312 |
| 720×1280(竖版) | 736×1312 | 736×1312 |
| 1024×1024(正方形) | 1024×1024 | 1024×1024 |
| 1500×1500(正方形·非标准档) | 1024×1024 | 1024×1024 |
| 2048×2048(正方形) | 2048×2048 | 2048×2048 |
规律:横版一律 1312×736、竖版一律 736×1312(请求多大都一样,请求比它小的还会被放大);正方形按档——1024×1024、2048×2048 给满(2048 偶尔较慢,实测 60-90s,偶尔更久),非标准档(如 1500×1500)压到 1024×1024。两个模型在这点上一模一样,没有差异。以上实际像素均由 PIL 直接读取 PNG 文件得到,不是看 API 返回的元信息。
所以并发测试用的 1920×1088 拿到的是 1312×736(横版档),图片测试统一用 1024×1024(正方形标准档,给满);想拿更大的正方形可以请求 2048×2048。
唯一要吐槽的是它 API 有个反直觉的坑:response_format 这个参数必须放在 extra_body 字段里,不能放在请求顶层,放顶层会报错。这种和 OpenAI 标准格式不一致的地方,官方文档没强调,得自己踩过坑才知道。
二、并发实测:能同时开多少路,瓶颈到底是什么
前面十道题都是串行的,一张跑完再跑下一张,大部分时间在等。一个很自然的问题:Agnes 图片接口能同时开多少路请求? 如果能并发,串行的等待能砍掉多少?
官方文档没给答案——只说”支持高并发”,没公开具体的同时能开多少路、或每分钟能发多少个请求。既然文档不写,那就只能测试。
测试方法
测试并发有个陷阱:Agnes 限制的到底是”同时能开几路”,还是”每分钟能发多少个请求”? 如果轮与轮之间间隔太短,前一轮把配额耗掉,后一轮就会被限流——这时测到的不是”同时能开几路的上限”,而是”每分钟配额”。为了排除这个干扰,测试方法上我做了三件事:
- 探针确认配额恢复:每个梯度之间、每轮之间,发单个”探针请求”,连续成功 2 次才认为配额干净,才开始下一轮。这样每一轮都是在干净状态下发出的。
- 验证内容完整性:图片请求不只看 HTTP 200,还要下载下来用 PIL 验证是有效图片(能 open、尺寸合理),否则算失败——200 不代表图真的生成了。
- 每个请求用不同提示词:24 个不同提示词轮换,避免缓存干扰。
另外我还给每个请求加了错误归因(error_kind 字段):区分是被限流(每分钟配额用完,通常要排队等几秒)、还是**“同时开太多路”被立刻拒(延迟不到 3 秒,说明撞到同时并发的上限)**、还是下载失败/图片无效。这个区分是判断”瓶颈到底是每分钟配额、还是同时能开几路”的关键。
梯度统一 1→8→16→24,每个跑 2 轮;另外单独跑一组持续出图测试——固定同时开 2 路不停跑满 3 分钟,专门看会不会被”每分钟配额”限住。
梯度结果:有上限,且和请求尺寸有关
图片接口(agnes-image-2.1-flash),探针确认 + PIL 内容验证,两个尺寸并排出:
| 并发数 | 1920×1088 成功率 | 1024×1024 成功率 |
|---|---|---|
| 1 | 100% | 100% |
| 8 | 94% | 94% |
| 16 | 53% | 97% |
| 24 | 33% | 77% |
注:两档的实际输出不一样——请求 1920×1088 实际只给 1312×736(约 0.97MP),请求 1024×1024 实际给满 1024×1024(1.05MP)。这点很关键,下面”上限和请求尺寸有关”的结论正是基于它。
两个关键现象:
- 1920×1088 时,并发到 16 就只剩 53%、24 路只剩 33%——而且每轮稳定成功约 8 个(16 路成功 8-9 个、24 路成功 8 个),超出的被拒。
- 换成 1024×1024,同样并发 16 能到 97%、24 路还有 77%——上限明显高得多。
这说明”同时能开几路”的上限和请求尺寸有关——请求尺寸越大,能同时开的越少。注意这里看的是”请求尺寸”不是”实际输出”:1920×1088 请求实际只输出 1312×736(0.97MP),比 1024×1024 的实际输出(1.05MP)还小,但能同时开的路数反而更少。所以 Agnes 是按请求时声明的尺寸算同时能开几路(请求阶段就按 1920×1088 预留算力,哪怕最后缩水输出),不是按实际输出像素。实用启示:别请求过大尺寸——请求 1920×1088 拿到的还是 1312×736,但”能同时开几路”的配额是按 1920×1088 扣的,等于多花了配额却没拿到更大的图。
瓶颈归因:是”每分钟请求数”,还是”同时能开几路”?
先说结论:瓶颈是”同时能开几路”的上限,不是”每分钟请求数”。 三条证据:
证据一:失败是”立刻被拒”(0.9 秒),说明是”同时只让 N 个跑”的限制。 看 1920×1088 同时开 16/24 路时那些失败请求的耗时——全是 0.9 秒左右(0.89/0.91/0.93/0.96…),是立刻被拒,而且每轮稳定成功约 8 个、多出来的才被拒。这种”同时只让 N 个在跑、多出来的立刻拒”的特征,指向的是**“同时能开几路”的上限**,而不是”每分钟配额”。(失败请求具体返回什么状态码没记录,但这不影响判断——关键是”立刻被拒”,“每分钟配额”由下面的持续出图测试排除。)
证据二:上限随请求尺寸变。 1024×1024 能同时开到 16 路(97%)、1920×1088 只能开到 8 路(53%)。“每分钟请求数”不会因为图片尺寸而变化;而且 1920×1088 的实际输出(1312×736,0.97MP)反而比 1024×1024(1.05MP)更小,所以不是按实际输出限的——是按请求时声明的尺寸限的(请求越大、同时能开的越少)。
证据三:低并发持续 3 分钟,一次都没被限流。 我专门跑了一组持续出图测试(同时固定开 2 路、不停跑 180s,刻意只开 2 路避开”同时能开几路”的上限,纯粹看”每分钟配额”会不会限):
| 尺寸 | 同时路数 | 持续 | 成功/总 | 被限流次数 | 每分钟出图 |
|---|---|---|---|---|---|
| 1920×1088 | 2 | 180s | 14/15 | 0 | ≈4.26 张/分 |
| 1024×1024 | 2 | 180s | 15/16 | 0 | ≈4.33 张/分 |
两个尺寸持续跑 3 分钟,一次都没被限流(唯一的失败是偶发的服务端 http 500 错误,不是限流)。如果”每分钟请求数”是瓶颈,低并发持续跑几分钟迟早会被限——但没有。说明”每分钟请求数”远没到瓶颈,真正的瓶颈是”同时能开几路”。
顺带给出读者最想要的那个数:一个 API Key 同时开 2 路不停跑,每分钟大约出 4 张图(两种尺寸差不多,因为同时只开 2 路、瓶颈在单张耗时 ~25s,不是被限流)。这是”同时 2 路”下的速度,不是最快的——把同时并发的路数开到上限(1920 约 8 路、1024 约 16 路),出图会更快。
这意味着什么
1920×1088 时同时能开约 8 路,1024×1024 能到约 16 路——对于”边生成边质检”的图片流水线来说够用。真正的瓶颈是和请求尺寸相关的”同时能开几路”上限(不是”每分钟请求数”),工程上把同时开的路数控制在上限以内、配好重试和排队,收益就稳稳拿到。偶尔会出现服务端 http 500(本次约 1/15 的概率),重试即可兜底。
三、深度小结:到底什么水平,免费用在哪
把图片模型、十道题都认真测了一遍,我可以给一个相对公允的结论了。
agnes-image 比我之前印象里能打。十道题复核下来,文字渲染(中英文)、风格/光影控制、手部解剖、语义合成、多主体、图生图(换背景 + 风格迁移)都过关。明确的短板有两个:
- 精确数量遵循(俯拍晚宴画得出,但画不出”恰好 6 套餐具”——视觉计数不稳,不列精确数;在免费 API 里,这是个常见问题)。
- 中文密集小字(思维导图方块下的密集小字说明崩——标题/分支名全对,但密集小字乱码;同样是免费 API 里的常见问题)。
前一篇里我说它”效果差,比稿定差一截”,这次要修正。至少在文字渲染和中文多物体组合这些经典题上,agnes-image-2.1-flash 的表现是过关的。我打算接下来重新把它接回封面图流程里,认真对比一下它和稿定,而不是凭印象一棍子打死。
2.0 vs 2.1 怎么选:需要色彩冲击力的插画/封面/海报选 2.0;需要细节扎实的写实场景或图生图基础选 2.1。两者主体正确性打平,差别在风格。我个人不想过多思考,直接用 2.1。
回到那个最初的问题:之前弃用 Agnes 出图那条判断,这次还成立吗?——不成立,该重新评估。
那具体什么时候用?我的结论很干脆:需要显示汉字的图,我还是不用 Agnes——中文渲染虽然标题级能对,但密集小字不稳,整体没到让我放心的程度,汉字场景我宁可选别的;但不涉及汉字的图(封面、插画、写实场景、图生图编辑),可以考虑用 Agnes 了,够用,还免费。
最后说一句关于”免费”本身。永久免费、无限期,听起来很美,但官方也说了每日调用有限制,真要上量,得多准备几个 API Key 轮换。免费的东西,拿来试水、做副链路、跑实验都没问题;但要拿它扛生产环境的主力,那个”每日限额 + 可能随时调整政策”的不确定性,始终是悬在头上的。免费是好东西,但别全指望它。
这次的收获,除了图片模型的实测数据,还有个更重要的:不带偏见地、用标准 benchmark 把一个工具认真测一遍,比凭一两次印象下结论,靠谱得多。 之前弃用,多少带点”顺手试试、不行就换”的随意;这次系统测完,哪些是真的不行、哪些是我当时没测对,才算有了实打实的依据。
工具会迭代,印象会过时,但”用经典 benchmark 认真测一遍”这个习惯,不会过时。
📌 这是 Agnes 实测系列的图片篇。下一篇我会实测它的视频模型,看看”文生视频太慢、画面不可控”那些槽点还成不成立。