基于深度度量学习的语义实例分割(Semantic Instance Segmentation via Deep Metric Learning)
论文提出一种语义实例分割的新方法,简单概括为先计算两个像素点属于同一个对象的可能性,然后将相似的像素分组到一起。相似度的度量方式取决于深度完全卷积的嵌入模型,而分组的方法是取决于用深度完全卷积的评分模型选取与一组“种子点”(seed point)足够相似的所有点。论文下载地址
论文前言(Introduction)
论文一介绍了语义实例分割 与物体检测的区别、 与语义分割的区别、 在领域中的实际应用、 常用的处理方法、 近期的新的处理方法、 论文中提出的语义实例分割新方法。
语义实例分割与物体检测的区别
相对于物体检测,结果不是一个边界框,而是实例对象的形状,
语义实例分割与语义分割的区别
相对于语义分割,语义实例分割不仅仅只是将每一个像素分类到一个标签,而且区分同一类别中的单个实体(即区分person-1、person-2……),因而标签空间的大小没有限制(即标签可能包含两个对象,也可能是三个,甚至是无限多个)。
语义实例分割在领域中的实际应用
自动驾驶汽车、机器人技术、图片编辑等等。
语义实例分割常用的处理方法
首先,用某种机制去预测对象的边界,例如用一个类级别(class-level)的对象检测器或者使用一个类不可知边界建议方法(class agnostic box proposal method)比如边界盒(EdgeBoxes)等等。
然后,对每一个建议的边界(proposed box)中进行分类和分割。
这种方法的缺点在于如果在建议的边界中不止存在一个实体,则这种方法可能会失败。
论文中还说,直观的来看,首先检测代表每个物体的遮罩(mark),然后再根据需要从中派生一个边界框感觉更“自然”(“natural”)。
需要注意的是边界框对于一些具体类别(例如车、行人)的物体形状是很好的近似,但是在其他一些类别中表现就不那么好了,比如椅子之类的“金属线”物体( “wirey” objects)、铰接在一起的人(articulated people)以及其他非轴对称的物体(non-axis-aligned objects)。
语义实例分割近期的新的处理方法
自由边界的方法(“Box-Free” Methods):这种方法试图直接预测每个物体的遮罩,最常用的方法是修改Faster RCNN框架,以便在每一个点,预测一个中心性分数(“centeredness” score,当前点作为一个实体对象的中心的可能性),二元对象遮罩(binary object mask)和类标签(class label),而不是通常的对象分数(“objectness” score),边界框和类标签,但是,这种方法要求整个对象实例都符合进行预测的单元的接收域(receptive field),对于细长结构(elongated
structures)来说,这是很困难的,它们可能跨越图片中的很多像素,另外,对于一些对象种类,中心的概念没有一个很好的定义。
论文中提出的语义实例分割新方法
核心思想是计算两个像素点属于同一个实例对象的可能性,随后用这些可能性来将相似的点分组。
相似于大多数无监督图像分割方法(unsupervised image segmentation),都将像素点分组到一起形成部分(segments)或者“超级像素”(“super-pixels”),然而,与无监督案例不同的是,论文中的方法对“正确的”部分有明确定义的概念,叫做整个对象的空间范围,这避免了像是否将一个对象的部分做一个独立的部分(例如,人的上衣和裤子)的这种歧义,而这是无监督方法的评估的困扰。
论文中的方法建议使用深度嵌入模型来学习相似度度量,这种方法与其他方法也有相似之处,比如FaceNet,它学习两个边界框属于同一个人的可能性,除了学习预测像素的相似性,同时考虑到它们本地的上下文。
文中提到文中的方法与无监督图像分割的另一个不同是没有使用基于谱或者图的划分方法,原因是,计算所有像素点成对的相似度太昂贵的,相反,使用了计算与一组K个种子点(“seed points”)的距离在嵌入空间中,这可以使用张量成发来实现。
为了找到这些种子点(seed points),学习一个单独的模型来预测一个像素点作为一个好的种子点的可能性,把这个叫做每个像素点的“种子度”分数(“seediness” score ),这类似于之前提到的方法中的“中心度”分数(“centeredness” score),只是不需要确定对象的中心,而是使用种子度分数的方法,度量一个像素相对于其他像素点“典型性”(“typicality”)在这个实体中。论文中表明,在实践中,只需要取前100个种子,就可以很好地覆盖一张图像中几乎所有的对象。
前言部分最后说了一下新方法的准确性,总结来说就是尽管在这个特定的基准(Pascal VOC 2012 instance segmentation
benchmark)下不是最先进的,但是依然有竞争力。
模型图
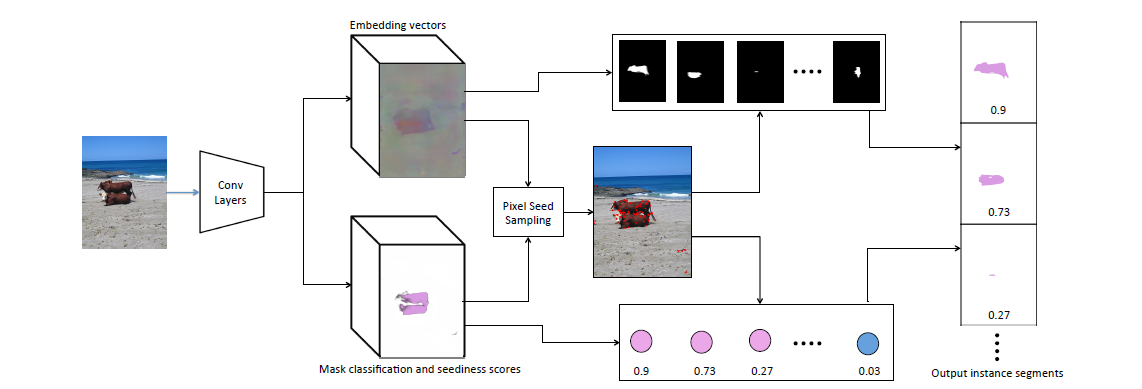
图片中展示了上面所说的过程:给定一张图片,先通过卷积层,通过卷积层之后,通过一个网络预测得到嵌入向量(embedding vector),同时通过另一个网络预测得到遮罩分类和种子度分数(Mask classification and seediness scores),随后通过这个两个结果又可以等到像素种子样本(Pixel Seed
Sampling),最后通过分组,得到最终的实体分割的结果(Output instance segments),包括了遮罩、分类的分数。
相关工作
论文的第二部分Related work,主要大概概述了一些语义实体分割的方法以及方法的优劣,最后到论文要提出的新方法,这里跳过,主要看第三部分,方法的详细说明。
论文中提出的方法
简单概述
这里用自己的话总结一下,论文中提出的方法,首先
- 图片(维度[h,w,3])通过一个特征提取器(基于DeepLab V2模型,修改掉最后分类的层(layer),让输出的维度为[h/8,w/8,2048]),
- 第一步的结果再通过嵌入模型(
embedding model)(输出维度为[h,w,d],这里的d为每一个像素点嵌入向量的维度,论文中设置d=64)。 - 这一步与第2步同时进行,第一步的结果再通过分类模型,输出为[h,w,C+1],C为分类的数目,对应每一个点分类的分数。
- 最后结合第2步,第3步,输出实体分割结果,取两者的重叠率,当重叠率最高的类别超过一个阈值({0.25,0.5,0.75,0.9})的时候,则该分类有效,作为遮罩的类别。
到这里基本实现了模型的正向传播,训练方法与预处理在这里先不详细总结了,对应上面四个步骤进行训练,第一步中,使用COCO预训练(DeepLab V2模型修改最后一层),第二步第三步中,使用类似交叉熵损失函数来训练,在选择种子点时,使用均方误差作为损失函数来训练,选择最合适的种子点。
以上是部分论文的直译,以及一些个人的理解,可能有些不准确的地方,之后有机会使用到论文中的方法时,再深入吧,这里算是了解一种新方法。